


Deep neural networks like convolutional neural networks (CNNs) have revolutionized various computer vision tasks, from image classification to object detection and segmentation. As models grew larger and more complex, their accuracy soared. However, deploying these resource-hungry giants on devices with limited computing power, such as embedded systems or edge platforms, became increasingly challenging.

Knowledge distillation (Fig. 2) emerged as a potential solution, offering a way to train compact “student” models guided by larger “teacher” models. The core idea was to transfer the teacher’s knowledge to the student during training, distilling the teacher’s expertise. But this process had its own set of hurdles – training the resource-intensive teacher model being one of them.
Researchers have previously explored various techniques to leverage the power of soft labels – probability distributions over classes that capture inter-class similarities – for knowledge distillation. Some investigated the impact of extremely large teacher models, while others experimented with crowd-sourced soft labels or decoupled knowledge transfer. A few even ventured into teacher-free knowledge distillation by manually designing regularization distributions from hard labels.

But what if we could generate high-quality soft labels without relying on a large teacher model or costly crowd-sourcing? This intriguing question spurred the development of a novel approach called ReffAKD (Resource-efficient Autoencoder-based Knowledge Distillation) shown in Fig 3. In this study, the researchers harnessed the power of autoencoders – neural networks that learn compact data representations by reconstructing it. By leveraging these representations, they could capture essential features and calculate class similarities, effectively mimicking a teacher model’s behavior without training one.
Unlike randomly generating soft labels from hard labels, ReffAKD’s autoencoder is trained to encode input images into a hidden representation that implicitly captures characteristics defining each class. This learned representation becomes sensitive to the underlying features that distinguish different classes, encapsulating rich information about image features and their corresponding classes, much like a knowledgeable teacher’s understanding of class relationships.
At the heart of ReffAKD lies a carefully crafted convolutional autoencoder (CAE). Its encoder comprises three convolutional layers, each with 4×4 kernels, padding of 1, and a stride of 2, gradually increasing the number of filters from 12 to 24 and finally 48. The bottleneck layer produces a compact feature vector whose dimensionality varies based on the dataset (e.g., 768 for CIFAR-100, 3072 for Tiny Imagenet, and 48 for Fashion MNIST). The decoder mirrors the encoder’s architecture, reconstructing the original input from this compressed representation.
But how does this autoencoder enable knowledge distillation? During training, the autoencoder learns to encode input images into a hidden representation that implicitly captures class-defining characteristics. In other words, this representation becomes sensitive to the underlying features that distinguish different classes.
The researchers randomly select 40 samples from each class to generate soft labels and calculate the cosine similarity between their encoded representations. This similarity score populates a matrix, where each row represents a class, and each column corresponds to its similarity with other classes. After averaging and applying softmax, they obtain a soft probability distribution reflecting inter-class relationships.
To train the student model, the researchers employ a tailored loss function that combines Cross-Entropy loss with Kullback-Leibler Divergence between the student’s outputs and the autoencoder-generated soft labels. This approach encourages the student to learn the ground truth and the intricate class similarities encapsulated in the soft labels.
Reference: https://arxiv.org/pdf/2404.09886.pdf
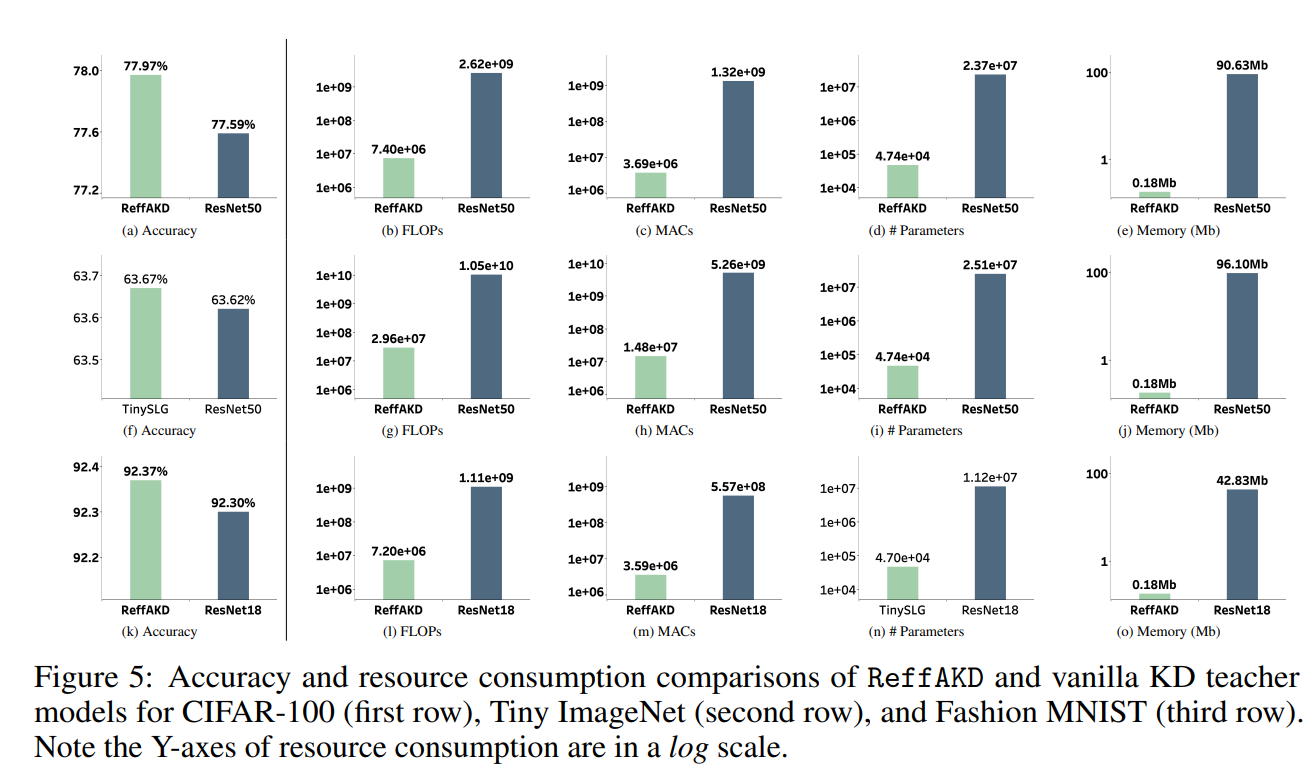
The researchers evaluated ReffAKD on three benchmark datasets: CIFAR-100, Tiny Imagenet, and Fashion MNIST. Across these diverse tasks, their approach consistently outperformed vanilla knowledge distillation, achieving top-1 accuracy of 77.97% on CIFAR-100 (vs. 77.57% for vanilla KD), 63.67% on Tiny Imagenet (vs. 63.62%), and impressive results on the simpler Fashion MNIST dataset as shown in Figure 5. Moreover, ReffAKD’s resource efficiency shines through, especially on complex datasets like Tiny Imagenet, where it consumes significantly fewer resources than vanilla KD while delivering superior performance. ReffAKD also exhibited seamless compatibility with existing logit-based knowledge distillation techniques, opening up possibilities for further performance gains through hybridization.
While ReffAKD has demonstrated its potential in computer vision, the researchers envision its applicability extending to other domains, such as natural language processing. Imagine using a small RNN-based autoencoder to derive sentence embeddings and distill compact models like TinyBERT or other BERT variants for text classification tasks. Moreover, the researchers believe that their approach could provide direct supervision to larger models, potentially unlocking further performance improvements without relying on a pre-trained teacher model.
In summary, ReffAKD offers a valuable contribution to the deep learning community by democratizing knowledge distillation. Eliminating the need for resource-intensive teacher models opens up new possibilities for researchers and practitioners operating in resource-constrained environments, enabling them to harness the benefits of this powerful technique with greater efficiency and accessibility. The method’s potential extends beyond computer vision, paving the way for its application in various domains and exploration of hybrid approaches for enhanced performance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
For Content Partnership, Please Fill Out This Form Here..
The post ReffAKD: A Machine Learning Method for Generating Soft Labels to Facilitate Knowledge Distillation in Student Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]