


Language model alignment has become a pivotal technique in making language technologies more user-centric and effective across different languages. Traditionally, aligning these models to mirror human preferences requires extensive, language-specific data, which is not always available, particularly for less common languages. This scarcity poses a significant barrier to developing practical and equitable multilingual models.
Researchers from MIT, Google Research, and Google DeepMind developed an innovative approach to align language models across languages without needing specific data for each language. Their technique, known as zero-shot cross-lingual alignment, leverages a reward model initially trained in one language (typically English) and applies it to other languages. This method bypasses the usual requirement for vast amounts of language-specific training data.
The research team demonstrated the effectiveness of this method using two primary tasks: text summarization and open-ended dialog generation. They employed two optimization strategies—reinforcement learning and best-of-n reranking—across several languages, including German, English, Spanish, Russian, Turkish, and Vietnamese. Their experiments highlighted that when applied to a different target language, the reward model maintained effectiveness, often surpassing traditional models aligned with language-specific data.
The success rate of models aligned using this method was impressive. For instance, in text summarization tasks, cross-lingually aligned models were preferred over unaligned models in more than 70% of cases evaluated by human judges. This indicates a strong preference for the outputs of the aligned models, underscoring the method’s practical utility.
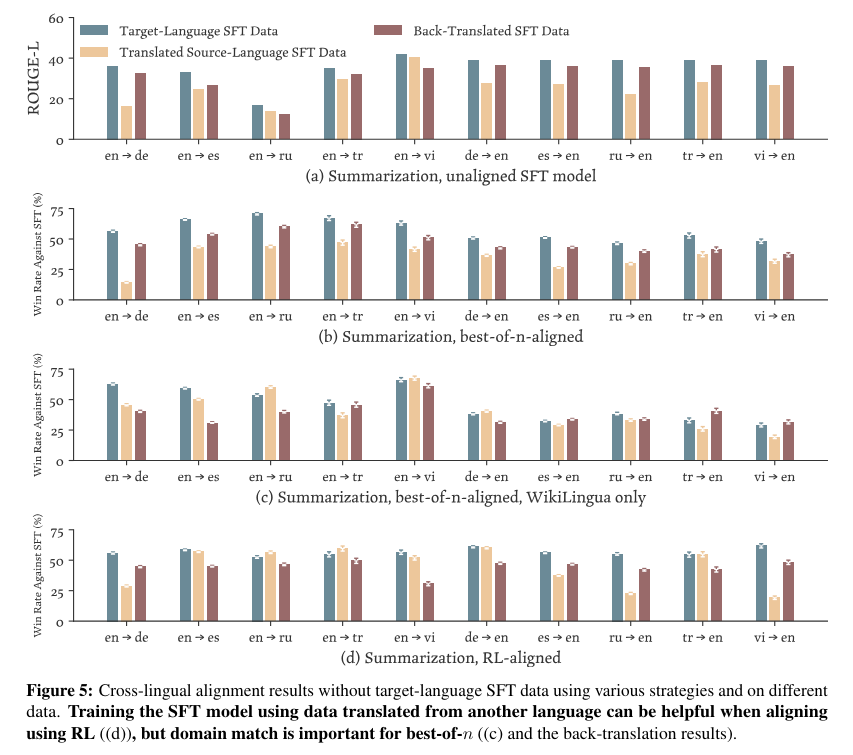
The research revealed some surprising findings regarding the efficiency of using reward models across languages. Sometimes, a reward model from a different source language yielded better results than one from the same target language. For example, using an English reward model to align a German language model often produced more aligned outputs than a German one.
The alignment improved model quality across all settings, with cross-lingual reward optimization showing enhancements in nearly every scenario tested. For dialog generation tasks, aligned models demonstrated a 20% to 30% improvement over baseline models regarding alignment accuracy with human preferences.

In conclusion, the research on zero-shot cross-lingual alignment tackles the challenge of language model alignment in the absence of extensive language-specific data. By utilizing a reward model trained in one language and applying it across other languages, the method significantly reduces the need for multilingual human-annotated data. Results indicate a strong preference for cross-lingually aligned models, with effectiveness sometimes surpassing models aligned with same-language data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
For Content Partnership, Please Fill Out This Form Here..
The post Transforming Language Model Alignment: Zero-Shot Cross-Lingual Transfer Using Reward Models to Enhance Multilingual Communication appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]