


The rise of Large Language Models (LLMs) has revolutionized Natural Language Processing (NLP), enabling significant progress in text generation and machine translation. A crucial aspect of these models is their ability to retrieve and process information from text inputs to provide contextually relevant responses. Recent advancements have seen a trend towards increasing the size of context windows, with models like Llama 2 operating at 4,096 tokens, while GPT-4 Turbo and Gemini 1.5 handle 128,000 and an impressive 10M tokens, respectively. However, realizing the benefits of a longer context window hinges on the LLM’s ability to recall information from it reliably.
With the proliferation of LLMs, evaluating their capabilities is crucial for selecting the most appropriate model. New tools and methods, such as benchmark leaderboards, evaluation software, and innovative evaluation techniques, have emerged to address this issue. “Recall” in LLM evaluation assesses a model’s ability to retrieve factoids from prompts at different locations, measured through the needle-in-a-haystack method. Unlike traditional Natural Language Processing metrics for Information Retrieval systems, LLM recall evaluates multiple needles for comprehensive assessment.
The researchers from VMware NLP Lab explore the recall performance of different LLMs using the needle-in-a-haystack method. Factoids (needles) are hidden in filler text (haystacks) for retrieval. Recall performance is evaluated across haystack lengths and needle placements to identify patterns. The study reveals that recall capability depends on prompt content and may be influenced by training data biases. Adjustments to architecture, training, or fine-tuning can enhance performance, offering insights for LLM applications.
The method assesses recall performance by inserting a single needle into a filler text haystack, prompting the model to retrieve it. Varying haystack lengths and needle positions analyze recall robustness and performance patterns. Heatmaps visualize results. Haystack length, measured in tokens, and needle depth, represented as a percentage, are varied systematically. Tests include 35 haystack lengths and placements for most models, adjusted for natural text flow. Prompts include a system message, a haystack with the needle, and a retrieval question.
Comparing recall performance across nine models on three tests reveals that altering a single sentence in a prompt filling a context window impacts an LLM’s recall ability. Increasing parameter count enhances recall capacity, as seen with Llama 2 13B and Llama 2 70B. Analysis of Mistral indicates architecture and training strategy adjustments can improve recall. Results for WizardLM and GPT-3.5 Turbo suggest fine-tuning complements recall capabilities.
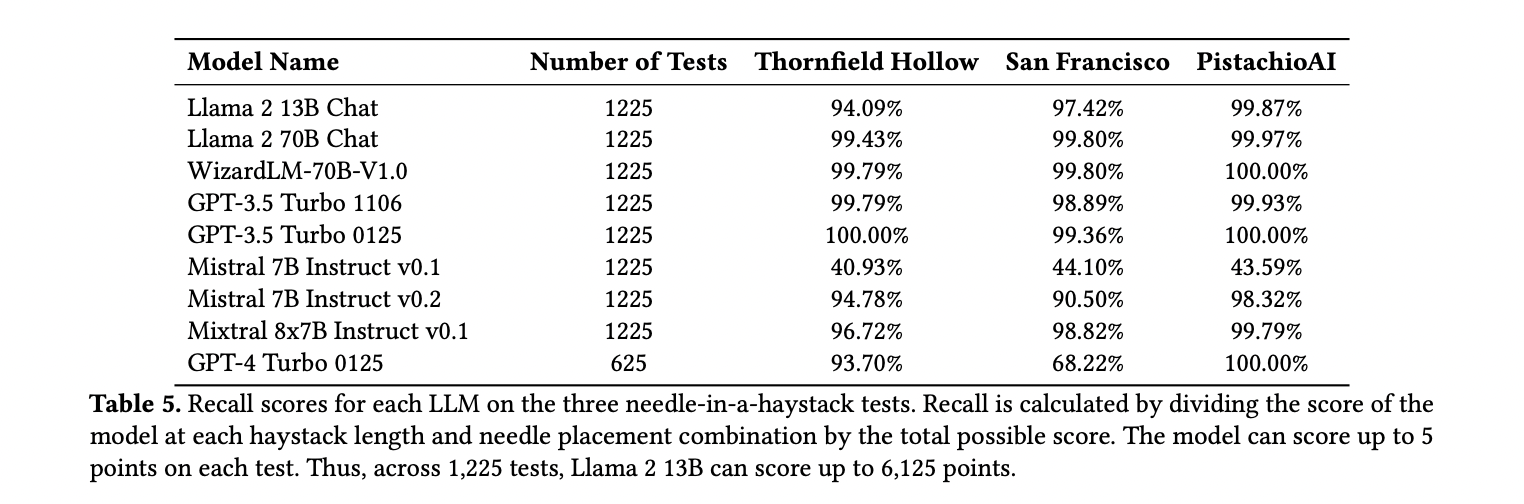
To conclude, This research explores the recall performance of different LLMs using the needle-in-a-haystack method. Their needle-in-a-haystack tests reveal that small changes in the prompt can significantly impact an LLM’s recall performance. Also, discrepancies between prompt content and model training data can affect response quality. Enhancing recall ability involves adjusting parameters, attention mechanisms, training strategies, and fine-tuning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
For Content Partnership, Please Fill Out This Form Here..
The post Unlocking the Recall Power of Large Language Models: Insights from Needle-in-a-Haystack Testing appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]