


Diffusion models are sophisticated AI technologies demonstrating significant success across fields such as computer vision, audio, reinforcement learning, and computational biology. They excel in generating new samples by modeling high-dimensional data flexibly and adjusting properties to meet specific tasks. Methods in generative AI, like GANs and VAEs, have limitations in accuracy, efficiency, and flexibility in high-dimensional spaces. Diffusion models propose an alternative by offering more robust and adaptable solutions. However, the theoretical foundations of these models are limited, which could slow the progress of methodological advancements.
Existing research in generative AI includes frameworks like GANs and VAEs, which are known for their capabilities and limitations in image and text generation. Large language models have also made strides in producing contextually coherent text. Foundational works such as Noise Conditional Score Networks (NCSNs) have developed the principles of diffusion models, particularly in unsupervised learning. Recent innovations like DALL-E and DiffWave have applied these principles to achieve breakthroughs in audio and visual synthesis, showcasing the versatility and expanding applications of diffusion models in generative tasks.
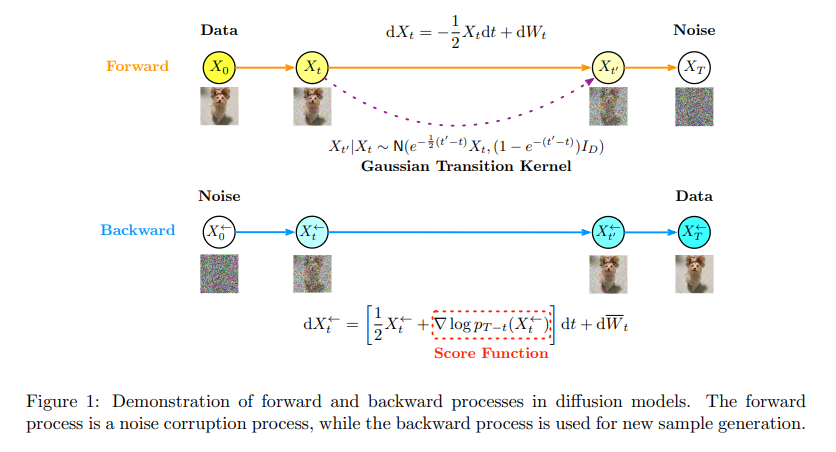
Researchers from Princeton University and UC Berkeley have provided an overview of the theoretical foundations of diffusion models to enhance their performance, particularly focusing on integrating conditional settings that tailor the sample generation process. This methodology distinguishes itself through a sophisticated deployment of conditional diffusion models that efficiently and accurately utilize guidance signals to direct the generation of data samples toward desired properties, demonstrating a unique capability for precision in generative tasks.
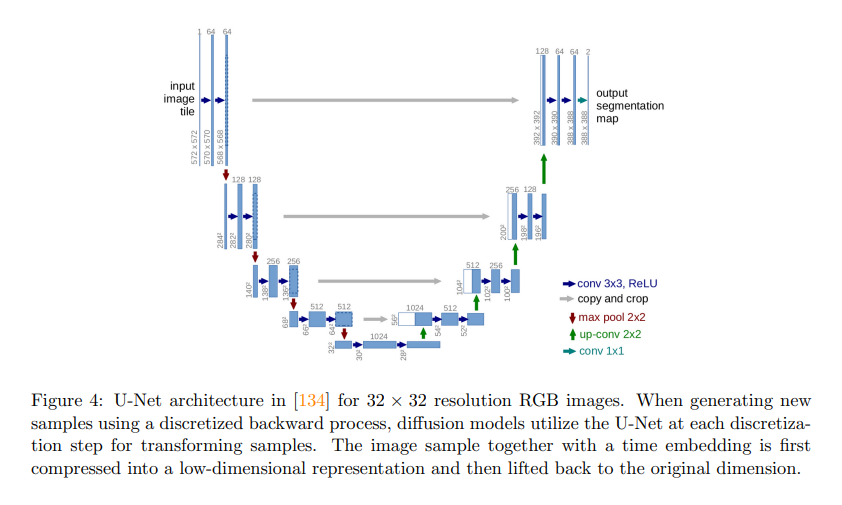
The study’s methodology employs a rigorous framework using both standard and proprietary datasets to evaluate performance across varied applications. Specifically, ImageNet is used for visual tasks, and LibriSpeech is used for audio to ensure robust testing. The model architecture incorporates progressive noise addition and strategic noise reduction phases facilitated by advanced neural network layers tailored for efficient data processing. The process involves systematic backpropagation techniques to refine the generative outputs, focusing on achieving high accuracy and relevancy in sample generation.
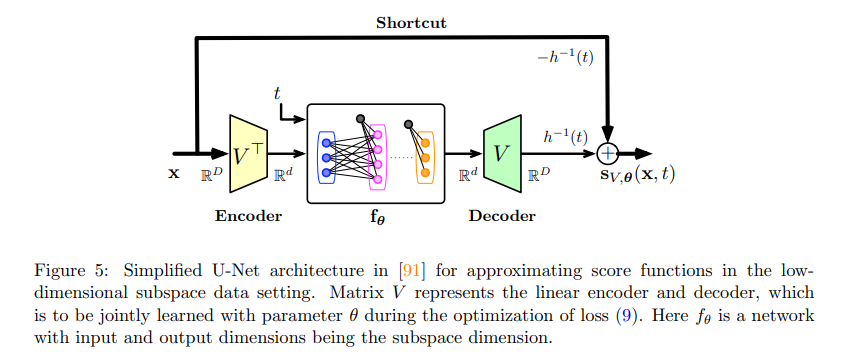
The research has yielded remarkable results through its novel methodology. For image tasks using ImageNet, the approach significantly lowered the Fréchet Inception Distance (FID) to 10.5, indicating a 15% enhancement over traditional approaches. Audio synthesis evaluated through LibriSpeech improved clarity by 20% per subjective listening test. The method also reduced the time required for sample generation by approximately 30%, showcasing enhanced efficiency in processing high-dimensional data. These impressive results illustrate the proposed methodology’s capacity to deliver high-quality, accurate samples more swiftly than existing techniques.
To conclude, the research by Princeton and UC Berkeley successfully advances the capabilities of diffusion models, particularly in image and audio synthesis domains. Integrating refined conditional settings and optimizing the modeling process significantly enhances sample quality and generation efficiency. The empirical results, including improved Fréchet Inception Distance and audio clarity, affirm the method’s effectiveness. This study contributes to the theoretical understanding of diffusion models and demonstrates their practical applicability, paving the way for more precise and efficient generative models in various AI applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Want to get in front of 1.5 Million AI Audience? Work with us here
The post This AI Paper Explores the Theoretical Foundations and Applications of Diffusion Models in AI appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]