


Large language models have recently brought about a paradigm change in natural language processing, leading to previously unheard-of advancements in language creation, comprehension, and reasoning. However, a troubling tendency that is concurrent with LLMs’ quick development is their propensity to induce hallucinations, leading to information that seems credible but lacks factual backing. The present definition of hallucinations, which describes them as created information that is illogical or disloyal to the given source content, is consistent with earlier studies. Based on the degree of discrepancy with the original material, these hallucinations are further divided into intrinsic and extrinsic hallucination categories.
While there are task-specific variants, this category is shared by several natural language-generating jobs. Compared to task-specific models, LLMs have a higher potential for hallucinations due to their exceptional adaptability and superior performance across several NLG tasks, especially in open-domain applications. Within LLMs, hallucination is a more expansive and all-encompassing notion focusing mostly on factual inaccuracies. The present hallucination taxonomy must be modified to improve its relevance and flexibility in light of the progress of the LLM era. A team of researchers from Harbin Institute of Technology, China, and Huawei have reclassified the hallucinatory taxonomy in this study, providing a more specialized foundation for LLM applications.
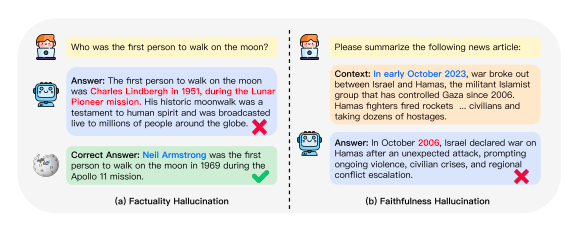
They divide hallucinations into two primary categories: fidelity hallucinations and factuality hallucinations. The emphasis of factual hallucination is on the differences between content that has been created and verified real-world facts; these differences usually show up as fabrications or factual inconsistencies. For instance, in response to a question concerning the first person to set foot on the moon, as shown in Fig. 1, the model would confidently answer that Charles Lindbergh did so in 1951. However, with the Apollo 11 mission in 1969, Neil Armstrong became the first to set foot on the moon. On the other hand, the term “faithfulness hallucination” describes the generated content’s inconsistency and departure from user instructions or the input’s context.
As seen in Figure 1, the model produced an erroneous event date for the confrontation between Israel and Hamas, mistaking October 2023 for October 2006 when asked to describe a news story. They further categorize factuality into two subcategories: factual inconsistency and factual fabrication, depending on the existence of verifiable sources. To improve fidelity, they place a strong emphasis on resolving inconsistency from the viewpoint of the user. They classify it into logical, context, and instruction inconsistencies. This better aligns it with how LLMs are currently used. Although they have been investigated in the context of NLG tasks, the fundamental causes of hallucinations pose special difficulties for state-of-the-art LLMs and merit further research.
Their thorough investigation focuses on the particular causes of hallucinations in LLMs, including a wide range of relevant elements from training and data to the inference phase. Inside this framework, they identify plausible data-related causes, including faulty sources and underutilized resources, subpar training strategies that could lead to pre-training and alignment hallucinations, and those resulting from stochastic decoding approaches and imprecise representations during inference.
Additionally, they provide a thorough description of a range of efficient detection techniques designed to identify hallucinations in LLMs and a thorough summary of benchmarks for LLM hallucinations. These are suitable testbeds for evaluating the degree of hallucinations produced by LLMs and the effectiveness of detection techniques. Additionally, they provide thorough tactics designed to lessen the recognized sources of hallucinations. They hope this particular study will further the field of LLMs and offer insightful information that will expand knowledge of the potential benefits and difficulties related to hallucinations in LLMs. Their comprehension of the shortcomings of the existing LLMs is improved by this investigation, which also offers crucial direction for further study and the creation of more reliable and strong LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post This AI Research from China Explores the Illusionary Mind of AI: A Deep Dive into Hallucinations in Large Language Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]