


The efforts to create models that can understand and process text with human-like accuracy are ongoing in natural language processing. Among the famous challenges, one stands out: crafting models that can efficiently convert vast amounts of textual information into a form that machines can understand and act upon. Text embedding models serve this purpose by transforming text into dense vectors, thereby enabling machines to gauge semantic similarity, classify documents, and retrieve information based on content relevance. However, creating such models previously relied on large, manually annotated datasets, a time- and resource-intensive process.
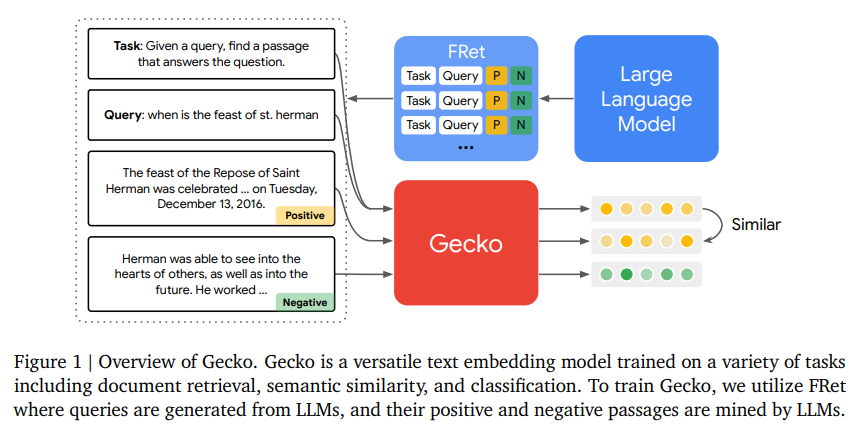
Researchers from Google DeepMind introduced Gecko, an innovative text embedding model. Gecko distinguishes itself by leveraging large language models (LLMs) for knowledge distillation. Unlike traditional models that depend on extensive labeled datasets, Gecko initiates its learning process by generating synthetic paired data through an LLM. This initial step produces a broad range of query-passage pairs that lay the groundwork for a diverse and comprehensive training dataset.
The team further refines the quality of this synthetic dataset by employing the LLM to relabel the passages, ensuring each query matches the most relevant passage. This relabeling process is critical, as it weeds out less relevant data and highlights the passages that truly resonate with the corresponding queries, a method that traditional models, limited by their datasets, often fail to achieve.
When benchmarked on the Massive Text Embedding Benchmark (MTEB), it demonstrated exceptional performance, outpacing models with larger embedding sizes. Gecko with 256 embedding dimensions outperformed all entries with 768 embedding sizes, and when expanded to 768 dimensions, it scored an average of 66.31. These figures are particularly impressive, considering Gecko competes against models seven times its size and with embedding dimensions five times higher.

Gecko’s main breakthrough lies in FRet, a synthetic dataset ingeniously crafted using LLMs. This dataset emerges from a two-tiered process in which LLMs first generate a broad spectrum of query-passage pairs, simulating diverse retrieval scenarios. These pairs are then refined, with passages relabeled for accuracy, ensuring each query aligns with the most relevant passage. FRet leverages the vast knowledge within LLMs to produce a diverse and precisely tailored dataset for advanced language understanding tasks.

In conclusion, Gecko’s development marks a notable advancement in employing LLMs to generate and refine its training dataset. It cuts the limitations of traditional dataset dependencies and sets a new benchmark for the efficiency and versatility of text embedding models. The model’s exceptional performance on the MTEB, coupled with its innovative approach to data generation and refinement, underscores the potential of LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Researchers at Google DeepMind Present Gecko: A Compact and Versatile Embedding Model Powered by the Vast World Knowledge of LLMs appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]