


The Dynamic Retrieval Augmented Generation (RAG) paradigm aims to improve the performance of LLMs by determining when to retrieve external information and what to retrieve during text generation. Current methods often rely on static rules to decide when to recover and limit retrieval to recent sentences or tokens, which may not capture the full context. This approach risks introducing irrelevant data and increasing computation costs unnecessarily. Effective strategies for optimal retrieval timing and crafting relevant queries are essential to enhance LLM generation while mitigating these challenges.
Researchers from Tsinghua University and the Beijing Institute of Technology have developed DRAGIN, a Dynamic Retrieval Augmented Generation framework tailored to LLMs. DRAGIN dynamically determines when and what to retrieve based on real-time information needs during text generation. It introduces RIND for timing retrieval, considering LLM uncertainty and token importance, and QFS for query formulation, leveraging self-attention across the context. DRAGIN outperforms existing methods across four knowledge-intensive datasets without requiring additional training or prompt engineering.
Single-round retrieval-augmented methods enhance LLMs by incorporating external knowledge retrieved using the initial input as a query. Previous studies extensively explore this approach, such as REPLUG, which uses LLMs to generate training data for retrieval models, and UniWeb, which self-assesses the need for retrieval. However, multi-round retrieval becomes essential for complex tasks requiring extensive external knowledge. Methods like RETRO and IC-RALM trigger retrieval at fixed intervals, but FLARE innovatively triggers retrieval upon encountering uncertain tokens, improving retrieval relevance by considering the LLM’s real-time information needs.
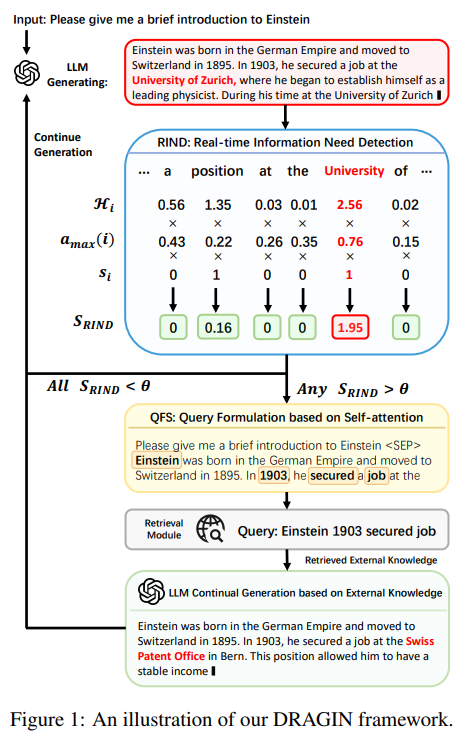
The DRAGIN framework comprises two key components: Real-time Information Needs Detection (RIND) and Query Formulation based on Self-attention (QFS). RIND evaluates tokens’ uncertainty, semantic significance, and impact on subsequent context to trigger retrieval dynamically. QFS formulates queries by analyzing the LLM’s self-attention mechanism, prioritizing tokens based on their relevance to the current context. After retrieval, the framework truncates the output at the identified token, integrates retrieved knowledge using a designed prompt template, and generates resumes. This iterative process ensures the LLM seamlessly incorporates relevant external information, enhancing its output’s quality and relevance.
The performance of DRAGIN was evaluated against various baseline methods across four datasets, and the experimental results were compared. DRAGIN consistently outperformed other methods, demonstrating its effectiveness in enhancing LLMs. Efficiency analysis revealed that DRAGIN required fewer retrieval calls than some baselines, indicating its efficiency. Timing analysis showed DRAGIN’s superiority in determining optimal retrieval moments based on real-time information needs. DRAGIN’s query formulation method outperformed other frameworks, emphasizing its ability to select tokens representing LLM’s information needs accurately. Furthermore, BM25 outperformed SGPT as a retrieval method, suggesting the continued effectiveness of lexicon-based approaches in RAG tasks.
In conclusion, DRAGIN is a framework addressing limitations in dynamic RAG methods for LLMs. DRAGIN improves retrieval activation timing with RIND and enhances query formulation precision using QFS, leading to better performance on knowledge-intensive tasks. Despite its reliance on Transformer-based LLMs’ self-attention mechanism, DRAGIN demonstrates effectiveness. Future work aims to overcome limitations related to self-attention accessibility. DRAGIN integrates external knowledge by truncating LLM output for retrieval augmentation and incorporating retrieved information using a prompt template. The impact of query formulation techniques is evaluated, with DRAGIN surpassing other methods like FLARE, FL-RAG, and FS-RAG.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post DRAGIN: A Novel Machine Learning Framework for Dynamic Retrieval Augmentation in Large Language Models and Outperforming Conventional Methods appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]