


With the incorporation of large language models (LLMs) in almost all fields of technology, processing large datasets for language models poses challenges in terms of scalability and efficiency. The core issue is the formidable task of managing, cleaning, and organizing massive datasets that are crucial for training sophisticated LLMs. Addressing this challenge requires a solution that is scalable, versatile, and accessible to a wide range of users, from individual researchers to large teams working on the state-of-the-art side of AI development.
Existing research emphasizes the significance of distributed processing and data quality control for enhancing LLMs. Utilizing frameworks like Slurm and Spark enables efficient big data management, while data quality improvements through deduplication, decontamination, and sentence length adjustments refine training datasets. The ETL (Extract, Transform, Load) process is also critical in aggregating and processing data from varied sources. Despite their effectiveness, these methods and frameworks must provide a unified, customizable solution for all LLM data processing needs.
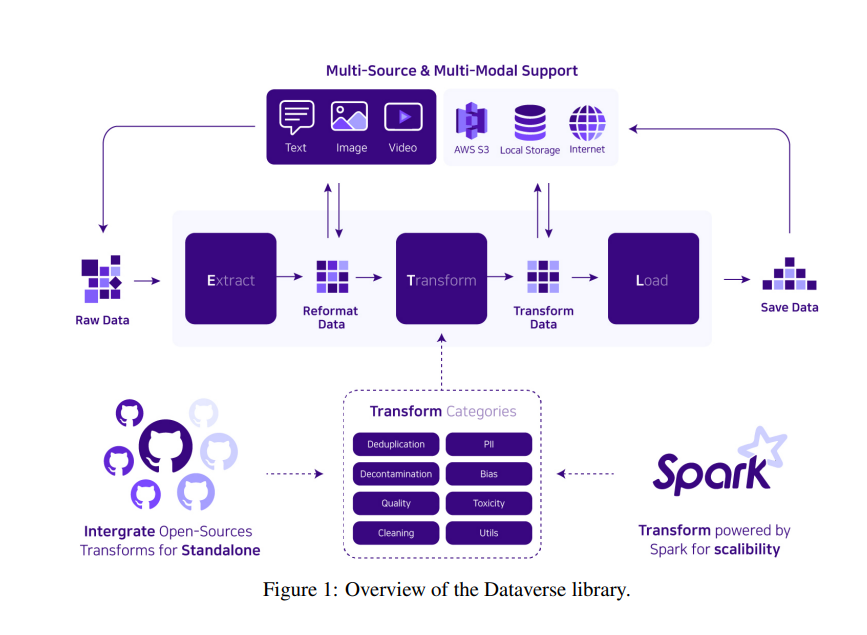
Researchers from Upstage AI have introduced Dataverse, an innovative ETL pipeline crafted to enhance data processing for LLMs. Dataverse stands out by offering a unified, customizable framework that simplifies the construction and modification of ETL pipelines, aiming to streamline data management and improve the development process of LLMs.
Dataverse’s methodology centers on a block-based interface for customizable ETL pipelines, utilizing Apache Spark for distributed processing and AWS for cloud-based scalability. It incorporates a decorator pattern for straightforward integration of custom data operations. The system is meticulously designed for high flexibility in data processing tasks, including deduplication, bias mitigation, and toxicity removal, without specifying the use of particular datasets in the paper. By enabling multi-source data ingestion—from local storage to cloud platforms and web scraping—Dataverse reassures you of its adaptability, facilitating efficient data preparation for LLM development and streamlining the workflow from data collection to processing.
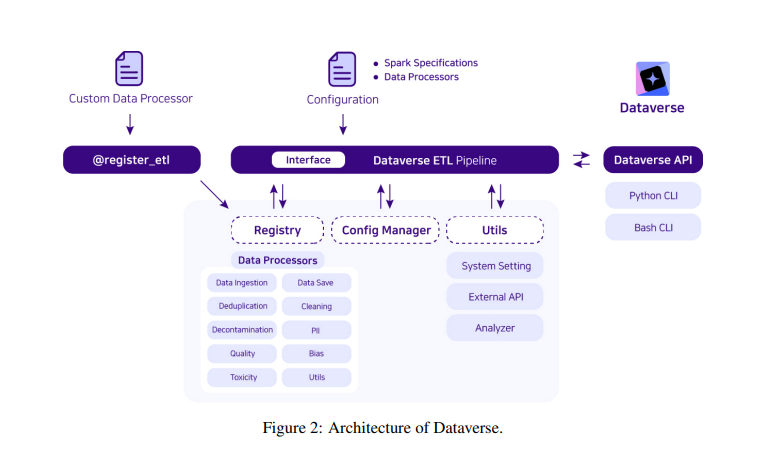
To conclude, the research conducted by Upstage AI introduces Dataverse, an open-source ETL pipeline designed to significantly improve the data processing for LLMs. By incorporating a block-based interface, Apache Spark, and AWS integration, Dataverse offers a scalable and customizable solution for managing large datasets. The tool’s emphasis on simplifying the ETL process and its potential to streamline the development of LLMs highlights its importance in advancing AI research. It inspires intrigue about its potential impact on data processing. Despite lacking quantitative results, Dataverse’s innovative approach marks a significant contribution to the field of data processing, sparking curiosity about its future applications.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Upstage AI Introduces Dataverse for Addressing Challenges in Data Processing for Large Language Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]