


Have you ever wondered what it would be like to have a super-intelligent AI assistant who not only has vast knowledge but also understands and respects your values, ethics, and preferences? A team of researchers may have cracked the code on making this sci-fi fantasy a reality.
Imagine having an AI companion that is extremely capable, yet operates with the same moral compass as you. It would never lie, mislead, or act against your interests. It would be bound by the same principles of honesty, integrity, and kindness that you hold dear. Sounds too good to be true? Well, the researchers at Upstage AI have developed an innovative technique that brings us one step closer to achieving this long-sought harmony between artificial and human intelligence.
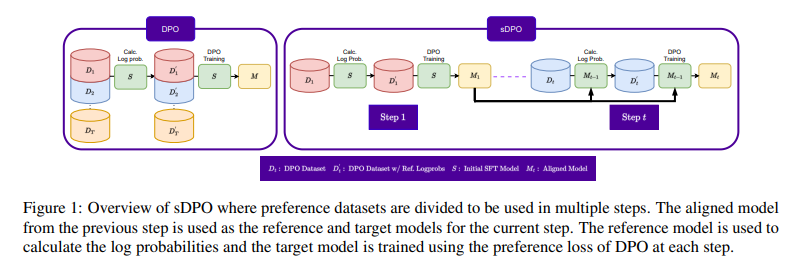
Their approach, called “stepwise Direct Preference Optimization” (sDPO), is an ingenious way to align large language models with human values and preferences. These models are the powerhouses behind AI assistants like ChatGPT. While extremely capable, they can sometimes respond in ways that seem at odds with what a human would prefer.
The key insight behind sDPO is to use a curriculum-style learning process to gradually instill human preferences into the model. It works like this: The researchers first collect data capturing human preferences on what constitutes good vs. bad responses to questions. This data is then split into chunks.
In the first phase, the AI model is trained on the first chunk while using its original, unrefined self as a reference point. This allows it to become slightly more aligned with human preferences than it was before. In the next phase, this more aligned version of the model now becomes the new reference point. It is trained on the second chunk of preference data, pushing it to become even better aligned.
This stepwise process continues until all the preference data has been consumed. At each step, the model is nudged higher and higher, climbing towards better harmony with human values and ethics. It’s almost like a seasoned human mentor passing on their wisdom to the model, one step at a time.
The results of the sDPO experiments are nothing short of remarkable. By fine-tuning the 10.7 billion parameter SOLAR language model using sDPO and leveraging two preference datasets (OpenOrca and Ultrafeedback Cleaned), the researchers achieved a level of performance that surpassed even larger models like Mixtral 8x7B-Instruct-v0.1.
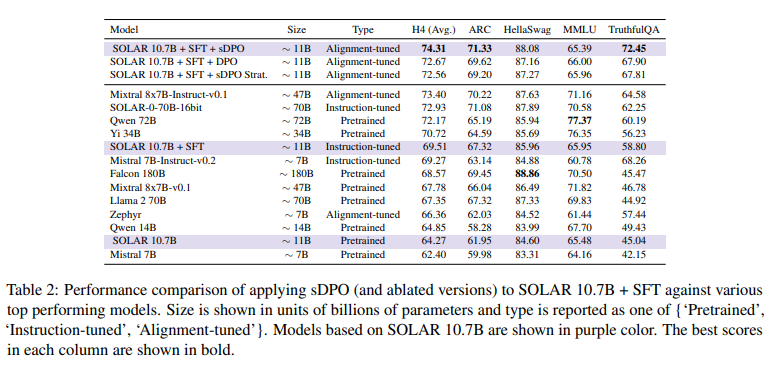
On the HuggingFace Open LLM Leaderboard, a benchmark for evaluating LLM performance, the sDPO-aligned SOLAR model achieved an average score of 74.31 across multiple tasks, outshining its larger counterparts. But perhaps even more impressive was its performance on the TruthfulQA task, where it scored a remarkable 72.45, showcasing its unwavering commitment to truthfulness – a core human value.
Behind these groundbreaking results lies a profound realization: effective alignment tuning can unlock superior performance, even for smaller language models. By leveraging a more aligned reference model at each step, sDPO equips these models with the ability to refine their understanding of human values continuously, ultimately enabling them to achieve unprecedented levels of capability while remaining firmly grounded in the principles that matter most to us.
As the researchers themselves acknowledge, the path to truly aligning AI with human values is an ongoing journey, one that requires a deeper understanding of dataset characteristics and their impact on performance. However, the success of sDPO provides a tantalizing glimpse into a future where artificial intelligence and human wisdom coexist in perfect harmony.
Imagine a world where AI systems not only possess remarkable capabilities but also embody the very values and principles that define our humanity – a world where machine intelligence is a reflection of our own aspirations, hopes, and desires. With groundbreaking techniques like sDPO, that future may be closer than we think.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Teaching SOLAR to Shine: How Upstage AI’s sDPO Aligns Language Models with Human Values appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]