


Information Retrieval (IR) involves technologies and models that allow users to extract relevant information from large datasets. This field has evolved significantly with modern computational techniques, facilitating more efficient and precise search capabilities across vast digital information landscapes. Despite advancements, a prevailing issue within IR is the limited interaction models between users and retrieval systems.
Existing IR systems heavily rely on models such as BM25, E5, and various neural network architectures, focusing primarily on enhancing semantic search capabilities through keyword-based queries and short sentences. Despite incorporating more sophisticated models like LLaMA 7B and the deployment of Large Language Models (LLMs) for semantic understanding, these strategies often need to pay more attention to the potential of utilizing detailed user instructions for refining search outcomes. Consequently, this overlooks an opportunity to fully exploit the advanced capabilities of LLMs in understanding and executing complex search intents.
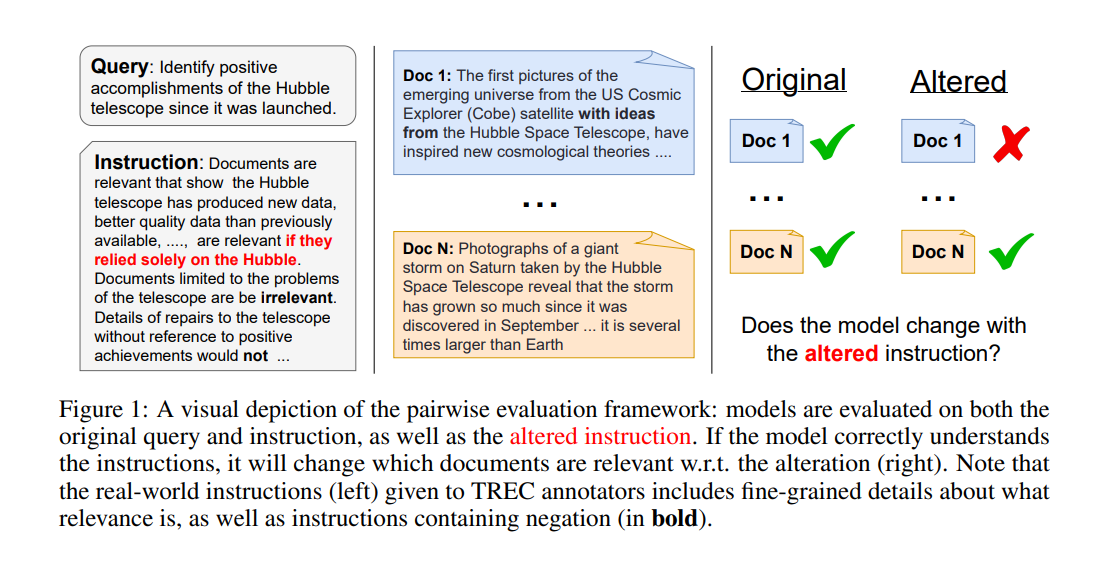
Researchers from Johns Hopkins University, Allen Institute for AI, University of Glasgow, and Yale University have introduced “FOLLOWIR,” a novel dataset and benchmark to enhance IR models’ capacity to interpret and follow detailed user instructions. This method leverages rich instruction sets derived from the TREC conferences, enabling IR models to grasp better and execute more complex search criteria as specified by users.
FOLLOWIR integrates three TREC collections: TREC News 2021, TREC Robust 2004, and TREC Common Core 2017. Expert annotators refine TREC instructions, focusing on documents initially marked relevant, effectively halving the pool of relevant documents for select queries from TREC Robust 2004 and TREC News 2021. Instruction-following is assessed using standard retrieval metrics alongside a novel metric, p-MRR, designed to gauge rank-wise shifts between queries. This approach factors in document ranking, offering a comprehensive score range. Results are averaged per query and across the dataset, with data presented in 400-word segments, adhering to the MTEB framework for distribution.
The evaluation encompassed models such as BM25, BGE-base, E5-base-v2, TART-Contriever, and INSTRUCTOR-XL, segmented into categories based on their training with no instructions, instructions in IR, API models, and instruction-tuned LLMs. Large models and those tuned for instruction adherence exhibited notable success in instruction following. However, while strong in standard IR metrics, API models faltered in following instructions. Instruction-tuned LLMs, particularly FOLLOWIR-7B, demonstrated positive outcomes, underscoring their adeptness at instruction-based tasks. Ablation studies revealed that models optimized for keyword search struggled with instruction length, suggesting a gap in handling detailed directives. This was consistent across various datasets, indicating a broader trend of challenges in instruction comprehension.
To conclude, the research introduces “FOLLOWIR,” a benchmark to assess instruction-following in IR models. It reveals that most, except for large or instruction-tuned LLMs, struggle with following detailed instructions. The creation of FOLLOWIR-7B, an instruction-tuned model, illustrates the potential for significant improvement in standard retrieval metrics and instruction adherence. Despite limitations like reranking versus full retrieval challenges and potential annotation errors, this research paves the way for developing advanced IR models capable of adapting to complex user instructions through natural language.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Revolutionizing Information Retrieval: How the FollowIR Dataset Enhances Models’ Ability to Understand and Follow Complex Instructions appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]