


Generative Language Models (GLMs) are being increasingly integrated into various sectors, including customer service and content creation, which necessitates maintaining a balance between moderation and freedom of expression. Hence, the need for a sophisticated approach to moderating potentially harmful content while preserving linguistic diversity and inclusiveness has never been more critical.
Toxicity scoring systems, designed to filter out offensive or harmful language, do help but often struggle with false positives, especially concerning language used by marginalized communities. This issue restricts access to relevant information and stifles cultural expression and language reclamation efforts, where communities reclaim pejorative terms as a form of empowerment. Current moderation methods predominantly rely on fixed thresholds for toxicity scoring, leading to rigid and often biased content filtering. This one-size-fits-all approach must account for language’s nuanced and dynamic nature, particularly how it is used in diverse communities.
Researchers from Google DeepMind and UC San Diego have introduced a novel concept: dynamic thresholding for toxicity scoring in GLMs. The proposed algorithmic recourse mechanism allows users to override toxicity thresholds for specific phrases while protecting them from unnecessary exposure to toxic language. Users can specify and interact with content within their tolerances of “toxicity” and provide feedback to inform future user-specific norms or models for toxicity.
Users are first allowed to preview content flagged by the model’s initial toxicity assessment. They can decide whether such content should bypass automatic filters in future interactions. This interactive process fosters a sense of agency among users and tailors the GLM’s responses to align more closely with individual and societal norms. The implementation of this model was rigorously tested through a pilot study involving 30 participants. This study was designed to gauge the usability and effectiveness of the proposed mechanism in real-world scenarios.
The dynamic thresholding mechanism demonstrated effectiveness by securing an average System Usability Scale score of 66.8. This outcome, coupled with the study’s participants’ positive feedback, underscores the dynamic system’s superiority over the traditional fixed-threshold model. Participants expressed significant appreciation for the enhanced control and engagement facilitated by the dynamic thresholding, as it allowed for a more tailored interaction experience by enabling adjustments to content filtering based on individual user preferences.
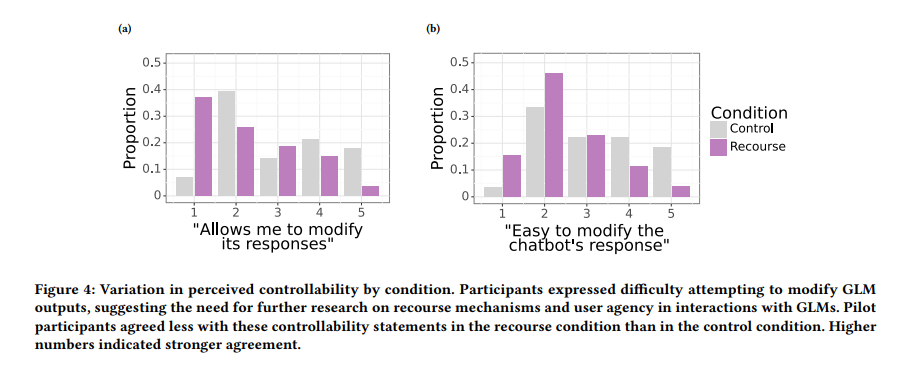
In conclusion, exploring dynamic thresholding for toxicity scoring in GLMs offers promising insights into the future of user experience and agency. It represents a significant step towards more inclusive and flexible technology that respects the evolving nature of language and the diverse needs of its users. However, further research is needed to fully understand the implications of this method and how it can be optimized for various applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Enhancing User Agency in Generative Language Models: Algorithmic Recourse for Toxicity Filtering appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]