


The performance of multimodal large Language Models (MLLMs) in visual situations has been exceptional, gaining unmatched attention. However, their ability to solve visual math problems must still be fully assessed and comprehended. For this reason, mathematics often presents challenges in understanding complex concepts and interpreting the visual information crucial for solving problems. In educational contexts and beyond, deciphering diagrams and illustrations becomes indispensable, especially when tackling mathematical issues.

Frameworks like GeoQA and MathVista have attempted to bridge the gap between textual content and visual interpretation, focusing on geometric queries and broader mathematical concepts. These models, including SPHINX and GPT-4V, have aimed to enhance multimodal comprehension by tackling diverse challenges, from geometric problem-solving to understanding complex diagrams. Despite their advances, a fully integrated approach to seamlessly combine textual analysis with accurate visual interpretation in the context of mathematical reasoning remains a frontier yet to be fully conquered.
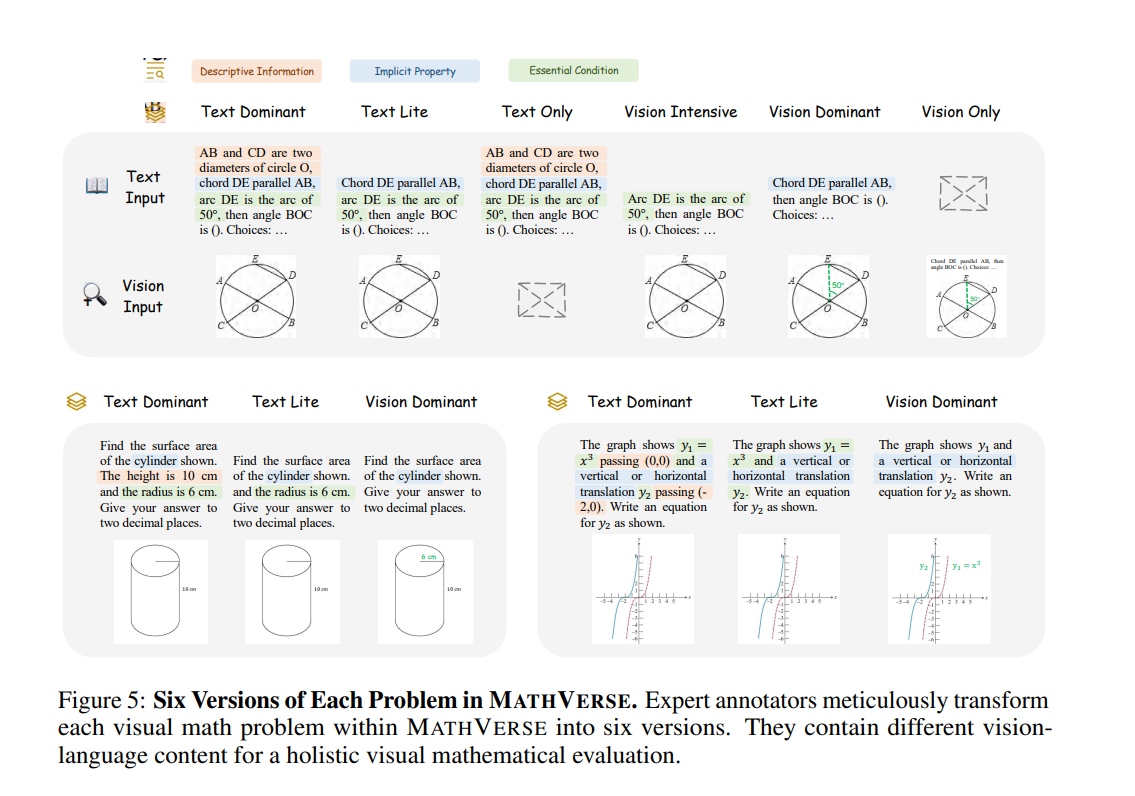
A research team from CUHK MMLab and Shanghai Artificial Intelligence Laboratory has proposed “MATHVERSE,” an innovative benchmark designed to rigorously evaluate MLLMs’ capabilities in interpreting visual information within mathematical problems. This approach introduces diverse math problems integrated with diagrams to test models’ understanding beyond textual reasoning.
MATHVERSE engages MLLMs with 2,612 math problems, each equipped with diagrams to challenge visual data processing. Researchers carefully adapted these problems into six distinct formats, ranging from text-dominant to vision-only, to dissect MLLMs’ multimodal analysis skills. Performance analysis revealed varying success; some models surprisingly improved by over 5% in accuracy when deprived of visual cues, hinting at a stronger textual than visual reliance. Particularly, GPT-4V demonstrated a balanced proficiency in text and vision modalities, offering a comprehensive insight into current MLLMs’ capabilities and limitations in handling visual and mathematical queries.
The evaluation on MATH VERSE highlighted that, while models like Qwen-VL-Max and InternLM-XComposer2 experienced a boost in performance (over 5% accuracy increase) without visual inputs, GPT-4V displayed more adeptness at integrating visual information, closely matching human-level performance in text-only scenarios. This variance underscores a reliance on text over visuals among MLLMs, with GPT-4V emerging as a notable exception for its comparative visual comprehension.
In conclusion, the research proposes a specialized benchmark called MATHVERSE to assess the visual, mathematical problem-solving capacity of MLLMs. The findings reveal that most existing models need visual input to understand mathematical diagrams and may even perform better. This suggests a crucial need for more advanced math-specific vision encoders, highlighting the potential future direction of MLLM development.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post MathVerse: An All-Around Visual Math Benchmark Designed for an Equitable and In-Depth Evaluation of Multi-modal Large Language Models (MLLMs) appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]