


In a collaborative effort that underscores the importance of interdisciplinary research, Tsinghua University and Microsoft Corporation researchers have unveiled LLMLingua-2. This groundbreaking study delves into language model efficiency, aiming to streamline communication between humans and machines and reduce the verbosity of natural language without compromising the conveyed information’s essence. The central challenge of this endeavor is the inherent redundancy in human language, which is beneficial for rich communication but often needs to be revised for computational processes.
The study identifies a critical bottleneck in the efficiency and generalizability of language model prompts. While effective for specific queries or tasks, traditional prompt compression methods falter when applied universally across different models and functions. This specificity results in increased computational and financial overheads, alongside degraded perception capabilities of the models due to lengthy prompts. Task-aware compression techniques, the prior norm, necessitate re-compression for varying tasks or queries, leading to inefficiencies.
The team has proposed a truly innovative approach to address these challenges: a data distillation procedure designed to distill essential information from large language models (LLMs) without compromising crucial details. This methodology is unique in its creation of a novel extractive text compression dataset coupled with a token classification model to ensure the compressed prompts’ fidelity to their original form. Unlike previous methods that might trim indiscriminately, this technique meticulously preserves the informational core, ensuring the utility and accuracy of the compressed prompts remain intact.
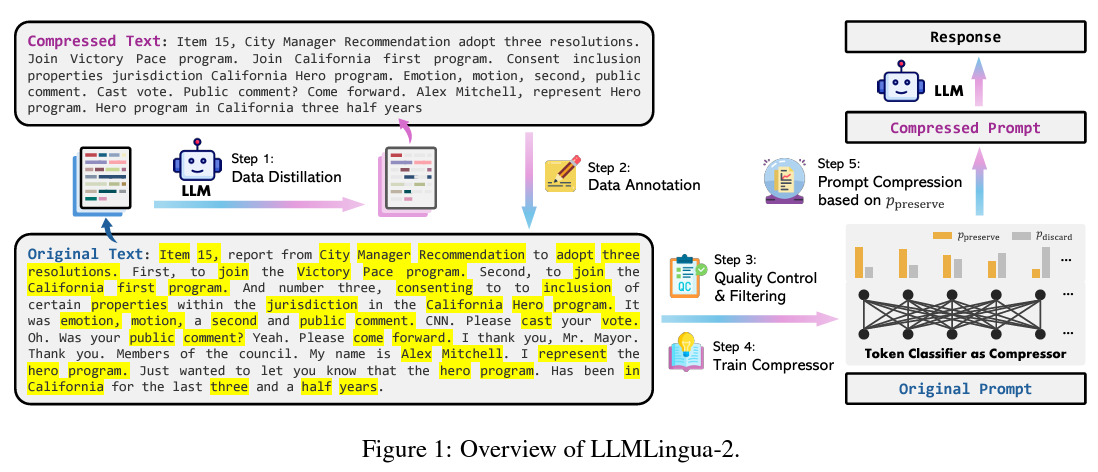
The technical foundation of this research is both innovative and robust. The proposed data distillation method leverages a token classification problem, positing prompt compression as a discerning task of preservation or discard. This nuanced approach, rooted in the full bidirectional context of the language, allows for a deeper understanding and retention of essential information. Employing a Transformer encoder as the backbone, the method capitalizes on the comprehensive context to optimize prompt compression. This strategy significantly diverges from earlier models that overlooked crucial details or failed to generalize across different tasks and models.
This new approach’s efficacy is theoretical and empirically validated across various benchmarks. The performance of the LLMLingua-2, even with its relatively smaller size compared to gargantuan models, marks a notable advancement in prompt compression techniques. In detailed evaluations, the model showcased substantial performance gains against strong baselines across in- and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K, and BBH. Remarkably, despite its compact architecture, the model achieved performance metrics that rivaled but, in some cases, surpassed those of its predecessors. It recorded a 3x-6x speed increase over existing methods, with an end-to-end latency acceleration of 1.6x-2.9x, alongside compression ratios ranging from 2x-5x.
This Tsinghua University and Microsoft Corporation study presents a versatile, efficient, and faithful method applicable to various tasks and language models by going beyond the conventional boundaries of prompt compression. The researchers have crafted a compression technique that maintains the integrity and richness of the original prompts while significantly reducing their size, paving the way for more responsive, efficient, and cost-effective language models. This significant advancement in task-agnostic prompt compression enhances the practical usability of LLMs and opens new avenues for research and application in computational linguistics and beyond.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Data Distillation Meets Prompt Compression: How Tsinghua University and Microsoft’s LLMLingua-2 Is Redefining Efficiency in Large Language Models Using Task-Agnostic Techniques appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]