


In the evolving landscape of computer vision, the quest for models that adeptly navigate the tightrope between high accuracy and low computational cost has led to significant strides. The field has oscillated between Convolutional Neural Networks (CNNs) and Transformer-based architectures, each with unique strengths and limitations. CNNs have been lauded for their ability to extract local features efficiently, laying the groundwork for nuanced image analysis without demanding extensive computational resources. On the flip side, Transformers have been celebrated for their global information processing prowess, albeit at the expense of heightened computational demands. This dichotomy has presented a formidable challenge: crafting an architecture that encapsulates the best of both worlds without compromising efficiency or performance.
A study by researchers from The University of Sydney introduces EfficientVMamba, a model that redefines efficiency in computer vision tasks. EfficientVMamba involves an innovative atrous-based selective scanning strategy with the principle of efficient skip sampling. This hybrid approach is designed to meticulously sift through visual data, capturing essential global and local features without burdening computational resources. The architecture distinguishes by integrating state space models (SSMs) with conventional convolutional layers, striking a delicate balance that has long eluded predecessors.
EfficientVMamba unveils an efficient visual state space block seamlessly converging with an additional convolution branch. A channel attention module further refined this intricate melding, ensuring a harmonious integration of features. The essence of this design lies in its dual-pathway approach, which adeptly navigates the complexities of global and local feature extraction. This strategic composition elevates model performance and significantly scales down computational complexity, setting a new precedent for efficiency.
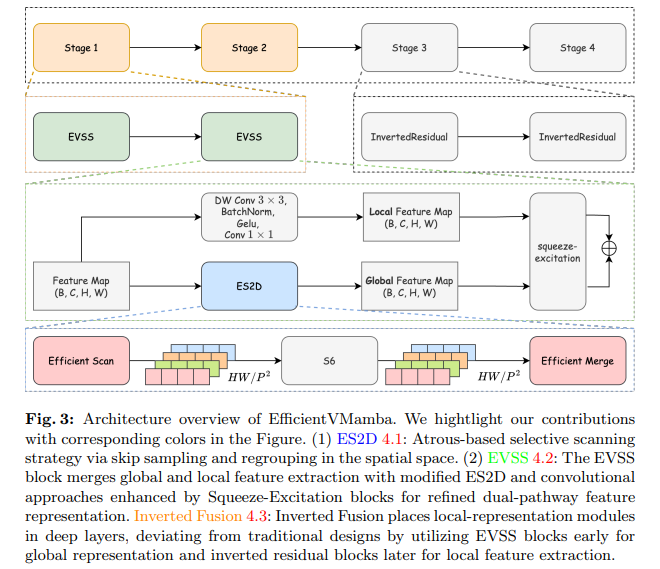
Empirical evidence underscores EfficientVMamba’s prowess across a spectrum of vision tasks, from image classification to semantic segmentation and object detection. The study intricately weaves atrous selective scanning with skip sampling, a convolutional branch, and state space models, crafting an architecture that transcends the conventional accuracy-efficiency trade-off. This fusion harnesses global and local information with unprecedented efficiency and opens the door to new possibilities in resource-constrained environments.
The model variant EfficientVMamba-S, with 1.3 GFLOPs, showcases a remarkable 5.6% accuracy improvement on ImageNet over its counterpart, VimTi, which operates at 1.5 GFLOPs. This numeric testament to the model’s efficiency is further supported by its comprehensive performance across a spectrum of vision tasks, including image classification, object detection, and semantic segmentation. For instance, in object detection tasks on the MSCOCO 2017 dataset, EfficientVMamba-T, with 13M parameters, achieves an AP of 37.5%, slightly edging out the performance of larger models such as ResNet-18, which has 21.3M parameters.
The model’s versatility is showcased in semantic segmentation tasks, where EfficientVMamba-T and EfficientVMamba-S variants achieve mIoUs of 38.9% and 41.5%, respectively, with significantly fewer parameters compared to benchmarks set by models like ResNet-50. This performance is significant to EfficientVMamba’s computational frugality and ability to deliver highly competitive accuracy across varied visual tasks.
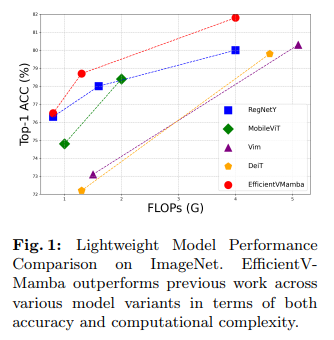
In conclusion, the inception of EfficientVMamba addresses a critical dilemma in computer vision: the trade-off between model accuracy and computational efficiency. By weaving together an innovative atrous-based selective scan with efficient skip sampling and a dual-pathway feature integration mechanism, EfficientVMamba sets a new standard for lightweight, high-performance models. The model’s ability to significantly reduce computational load while maintaining, and in some cases surpassing, the accuracy of more demanding architectures illuminates a path forward for future research and application in resource-constrained environments.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
The post This AI Paper from The University of Sydney Proposes EfficientVMamba: Bridging Accuracy and Efficiency in Lightweight Visual State Space Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]