


Pre-trained language models (PLMs) have revolutionized artificial intelligence, mimicking human-like understanding and text generation. However, the challenge of aligning these models with human preferences has emerged. In this context, the KAIST AI team introduces a novel approach, Odds Ratio Preference Optimization (ORPO), which promises to revolutionize model alignment and set a new standard for ethical AI.
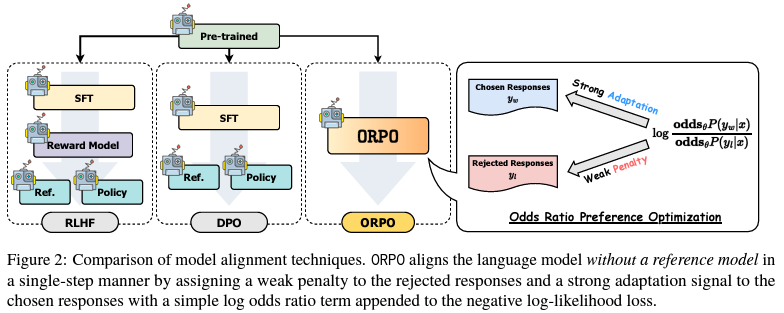
Traditional methodologies for enhancing PLM alignment have predominantly leaned on supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF). These processes, however, are not without their complexities; they typically involve a multi-stage alignment procedure that necessitates additional reference models, making the training both resource-intensive and time-consuming. The introduction of ORPO marks a departure from this convoluted path, offering a streamlined, efficient solution. By integrating preference alignment directly into the SFT phase, ORPO eliminates the need for a separate reference model, significantly simplifying the model training process.
The brilliance of ORPO lies in its simplicity and effectiveness. This innovative method adopts a monolithic approach, using a novel odds ratio-based penalty within the conventional negative log-likelihood loss function. This allows for a direct contrast between favored and disfavored response styles during the SFT process, enhancing the model’s ability to generate responses that are not only relevant but also ethically aligned with human values. The implications of this are profound, as it enables the development of AI systems that better understand and adhere to the nuanced preferences of human users, providing a practical and effective solution to the challenge of aligning models with human values.
Empirical evidence underscores the robustness and versatility of ORPO. The team demonstrated its effectiveness by applying it to various large-scale language models across various benchmarks, including Phi-2 and Llama-2. The results were remarkable. Models fine-tuned with ORPO exhibited superior performance, surpassing existing state-of-the-art models in tasks such as instruction following and machine translation. For instance, in the AlpacaEval2.0 benchmark, models fine-tuned with ORPO achieved a performance boost, with scores reaching up to 12.20% and 66.19% in IFEval (instruction-level loose accuracy), demonstrating the method’s potential to elevate model performance significantly and instilling confidence in its capabilities.
What sets ORPO apart is its efficacy in enhancing model performance and its contribution to making AI development more resource-efficient. By eliminating the need for additional reference models, ORPO paves the way for faster, more economical model development processes. This is particularly beneficial in a field where innovation is relentless and the demand for ethically aligned, high-performing AI systems is ever-increasing.
The introduction of ORPO by the KAIST AI team marks a significant milestone in artificial intelligence. This method simplifies model alignment and advances our ability to develop AI systems that align with human values. Beyond technical efficiency and performance, ORPO embodies the vision of creating AI that respects the ethical dimensions of human preferences. In the journey of AI evolution, ORPO leads innovation toward a future where AI and human values are in harmony.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
The post This AI Paper from KAIST AI Unveils ORPO: Elevating Preference Alignment in Language Models to New Heights appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]