


Large language models (LLMs) have taken center stage in artificial intelligence, fueling advancements in many applications, from enhancing conversational AI to powering complex analytical tasks. Their crux of functionality lies in their ability to sift through and apply a vast repository of encoded knowledge acquired through exhaustive training on wide-ranging datasets. This strength also poses a unique set of challenges, chiefly the issue of knowledge conflicts.
Central to the knowledge conflict dilemma is the clash between LLMs’ static, pre-learned information and the constantly evolving, real-time data they encounter post-deployment. This is not merely an academic concern but a practical one, affecting the models’ reliability and effectiveness. For instance, when interpreting new user inputs or current events, LLMs might reconcile this fresh information with their existing, possibly outdated, knowledge base.
Researchers from Tsinghua University, Westlake University, and The Chinese University of Hong Kong have surveyed the research done on this issue and presented how the research community is actively exploring avenues to mitigate the impact of knowledge conflicts on LLM performance. Earlier approaches have centered around periodically updating the models with new data, employing retrieval-augmented strategies to access up-to-date information, and continuous learning mechanisms to integrate fresh insights adaptively. While valuable, these strategies often need to be revised to fully bridge the gap between the static nature of LLMs’ intrinsic knowledge and the dynamic landscape of external data sources.
The survey shows how the research community has introduced novel methodologies to enhance LLMs’ capacity to manage and resolve knowledge conflicts. This ongoing effort, driven by a collective determination, involves developing more sophisticated techniques for dynamically updating models’ knowledge bases and refining their ability to distinguish between varying sources of information. The involvement of leading tech companies in this research underscores the critical importance of making LLMs more adaptable and trustworthy in handling real-world data.
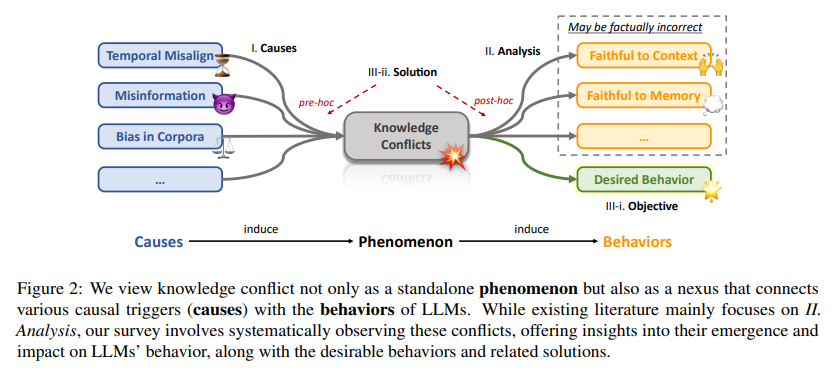
Through a systematic categorization of conflict types and the application of targeted resolution strategies, significant strides have been made in curtailing the spread of misinformation and boosting the overall accuracy of LLM-generated responses, providing reassurance about the positive direction of the research. These advances reflect a deeper understanding of the underlying causes of knowledge conflicts. This includes recognizing the distinct nature of disputes arising from real-time information versus pre-existing data and implementing solutions tailored to these specific challenges.
In conclusion, exploring knowledge conflicts in LLMs underscores a pivotal aspect of artificial intelligence research: the perpetual balancing act between leveraging vast amounts of stored knowledge and adapting to the ever-changing real-world information. Researchers have also illuminated the implications of knowledge conflicts beyond mere factual inaccuracies. Recent studies have focused on LLMs’ ability to maintain consistency in their responses, particularly when faced with semantically similar queries that might trigger conflicting internal data representations.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
The post Survey of Knowledge Conflicts in Large Language Models: Pathways to Enhanced Accuracy and Reliability appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]