


Bridging the divide between the visual world and the domain of natural language has emerged as a crucial frontier in the rapidly evolving realm of artificial intelligence. This intersection explored through vision-language models, aims to decipher the intricate relationship between images and text. Such advancements are pivotal for various applications, from enhancing accessibility to providing automated assistance in diverse industries.
Pursuing models adept at navigating and interpreting the wide-ranging complexities of real-world visuals and textual data has unveiled significant challenges. These include the need for models to recognize, understand, and contextualize visual information within the nuances of natural language. Despite considerable progress, existing solutions often need to be revised regarding data comprehensiveness, processing efficiency, and visual and linguistic elements integration.
Researchers from DeepSeek-AI have introduced DeepSeek-VL, a groundbreaking open-source Vision Language (VL) Model. This initiative is a testament to DeepSeek-AI’s pioneering spirit, marking a significant stride in the vision-language modeling arena. DeepSeek-VL’s introduction heralds a paradigm shift, offering innovative solutions to longstanding obstacles in the field.
Its nuanced approach to data construction is central to DeepSeek-VL’s success. The model leverages many real-world scenarios, ensuring a rich and varied dataset. This foundational diversity is critical, equipping the model to tackle various tasks with remarkable efficiency and precision. Such inclusivity in data sources enables DeepSeek-VL to adeptly navigate and interpret the complex interplay between visual data and textual narratives.
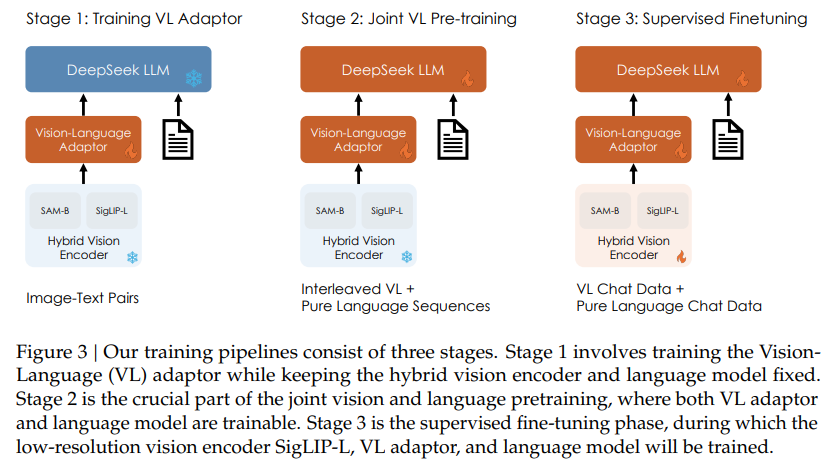
Further distinguishing DeepSeek-VL is its sophisticated model architecture. It introduces a hybrid vision encoder capable of processing high-resolution images within manageable computational parameters, representing a leap in addressing common bottlenecks. This architecture facilitates the detailed analysis of visual information, enabling DeepSeek-VL to excel across various visual tasks without sacrificing processing speed or accuracy. This strategic architectural choice underscores the model’s capability to deliver unparalleled performance, advancing the vision-language understanding field.
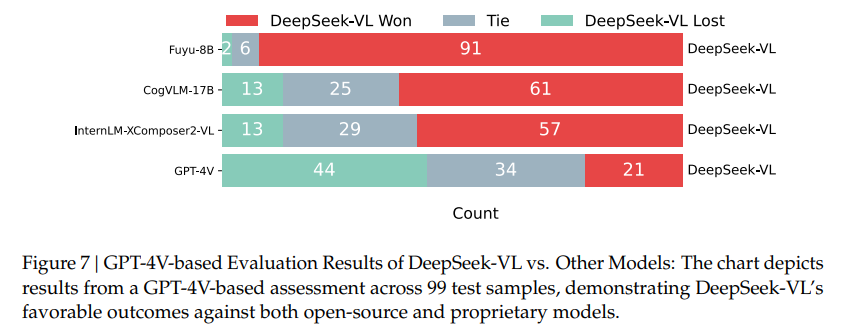
The efficacy of DeepSeek-VL is borne out through rigorous performance evaluations. DeepSeek-VL showcases its exceptional ability to understand and interact with the visual and textual world in these assessments. The model demonstrates a robust balance between language understanding and vision-language tasks by achieving state-of-the-art or competitive performance across various benchmarks. This equilibrium indicates DeepSeek-VL’s superior multimodal understanding, establishing a new standard in the domain.
In synthesizing the achievements and innovations of DeepSeek-VL, several key points emerge:
- DeepSeek-VL epitomizes the cutting edge in vision-language models, bridging the gap between visual data and natural language.
- The model’s comprehensive approach to data diversity ensures it is well-equipped to handle the complexities of real-world applications.
- With its innovative architecture, DeepSeek-VL processes detailed visual information efficiently, setting a benchmark in the field.
- Performance evaluations underscore DeepSeek-VL’s exceptional capabilities, marking it a pivotal advancement in artificial intelligence.
These attributes collectively underscore DeepSeek-VL’s role in propelling forward the understanding and application of vision-language models. By tackling key challenges with innovative solutions, DeepSeek-VL enhances existing applications and paves the way for new possibilities in artificial intelligence. The collaborative efforts of the research team, from data construction to model architecture and strategic training approaches, lay a solid groundwork for continued advancements in the field.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post DeepSeek-AI Introduces DeepSeek-VL: An Open-Source Vision-Language (VL) Model Designed for Real-World Vision and Language Understanding Applications appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MultimodalAI #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]