


Integrating APIs into Large Language Models (LLMs) represents a significant leap forward in the quest for highly functional AI systems capable of performing complex tasks such as hotel bookings or job requisitions through conversational interfaces. This advancement, however, hinges on the LLMs’ ability to accurately detect APIs, fill required parameters, and sequence API calls based on user utterances. The bottleneck in achieving these capabilities has been the scarcity of diverse, real-world training and benchmarking data, which is crucial for models to generalize well outside their training domains.

To tackle this, this paper introduces a novel dataset named API-BLEND (Figure 2), marking a significant departure from the reliance on synthetically generated data, which often suffers from issues like bias and lack of diversity. API-BLEND is a hybrid dataset enriched by human-annotated data and LLM-assisted generation, covering over 178,000 instances across training, development, and testing phases. This dataset is unique in its scale and focuses on sequencing tasks—a critical aspect often overlooked in existing datasets. API-BLEND offers an unprecedented variety of API-related tasks by incorporating data from diverse domains such as semantic parsing, dialog, and digital assistance.
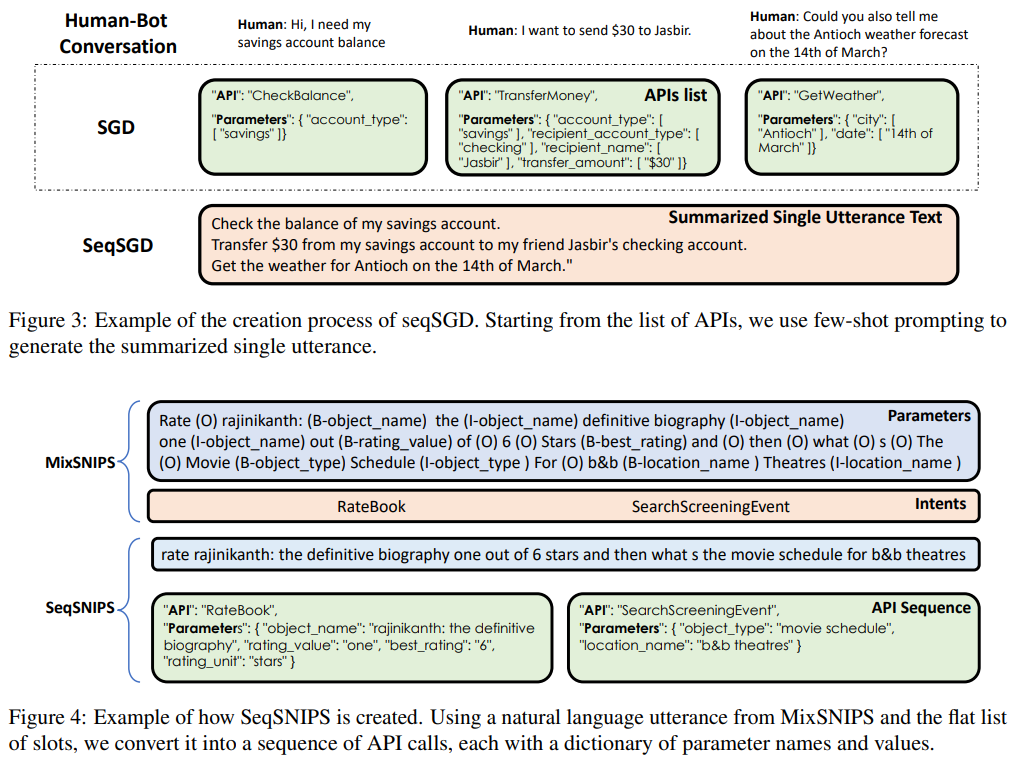
The core of API-BLEND’s innovation lies in its comprehensive approach to data curation, spanning language model-assisted generation, grammar-based generation, and direct inclusion of off-the-shelf datasets. This multifaceted strategy ensures a rich blend of API sequences, parameters, and contexts, aiming to address the complexity of real-world API usage in LLMs. The dataset includes sequences derived from existing dialogues, converted into API calls through advanced models like FLAN-T5-XXL, and further enriched by grammar rule-based transformations and pre-existing datasets adapted for API sequence evaluation.
Empirical evaluations have positioned API-BLEND as a superior training and benchmarking tool compared to other datasets, with models trained on API-BLEND demonstrating significantly better out-of-domain (OOD) generalization. This is evidenced by the performance of models fine-tuned with API-BLEND data across various OOD tests, where they outperform other API-augmented LLMs, showcasing their enhanced ability to navigate the complexities of API integration.
Furthermore, API-BLEND has been rigorously benchmarked against nine open-sourced models across a range of settings, including few-shot testing, instruction fine-tuning on target datasets, and combined dataset fine-tuning. The results underscore the robustness of API-BLEND in training models that excel in API detection, parameter filling, and sequencing—critical for executing complex tasks through conversational AI. Notably, models trained on the combined API-BLEND datasets achieved commendable performance across individual datasets, highlighting the dataset’s role in fostering a versatile and adaptable understanding of API interactions in LLMs.
In summary, API-BLEND emerges as a vital resource for developing and benchmarking tool-augmented LLMs, bridging the gap between synthetic data limitations and the need for real-world applicability. By offering a diverse, comprehensive corpus, API-BLEND advances state-of-the-art API-integrated language models and sets a new dataset diversity and utility standard. As the field moves forward, the exploration of environment interactions and multilingual API commands represents exciting avenues for further enhancing the practicality and reach of API-augmented AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post IBM AI Research Introduces API-BLEND: A Large Corpora for Training and Systematic Testing of Tool-Augmented LLMs appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]