


Recent advancements in language technology have revolutionized the adaptation of Large Language Models (LLMs), leveraging extensive in-domain datasets or even just a handful of task-specific examples. LLMs show remarkable zero-shot capabilities by simply learning to predict the next token at scale. By fine-tuning these models on instruction-tuning datasets containing many tasks, each comprising an input instruction and a desired response, the model generally improves its ability to respond to unseen instructions. If we talk about datasets like the Public Pool of Prompts (P3), Natural Instructions, and Dolly-v2, they are focused on text from the Web, classic natural language datasets.
However, LLMs have limitations if used in generalized domains. How can language models be adapted to follow instructions in specialized domains without annotated data? The ability to follow task-specific instructions in technical domains is important for bringing the benefits of LLMs to a wider range of users. Self-supervision in the form of next-word prediction on the target corpus is a simple way to teach language models about new domains. However, this approach requires enormous training to achieve strong performance.
Researchers from Brown University have proposed Bonito, an open-source model for conditional task generation to convert the user’s unannotated text into task-specific instruction-tuning datasets. Bonito enhances the performance of pretrained and instruction-tuned models beyond the standard self-supervised baseline, exemplified by a remarkable 22.1 F1 point increase in strong zero-shot performance when applied to Mistral-Instruct-v2 and its variants. It underscores the potential for even task-specialized models to enhance further through learning on Bonito-generated tasks.
Bonito is trained by fine-tuning Mistral-7B, an open-source decoder language model, on the CTGA dataset. To enhance model performance, training with more synthetic instructions on datasets like PubMedQA and Vitamin C is carried out. Finally, we perform additional experiments by prompting off-the-shelf open-source models like Zephyr-7B-β and Mistral 7B-Instruct-v0.2 and GPT-4 to generate tasks and find they can often improve the pretrained models but still struggle to increase model performance further when they are instruction tuned. Typically, pretrained models are trained to follow instructions on large-scale training mixtures such as P3 and the FLAN collection.
Bonito improves over the self-supervised baseline by an average of 33.1 F1 points on the pretrained models and 22.9 F1 points on the instruction-tuned models. The use of P3 to create meta-templates and train Bonito to generate NLP tasks in specialized domains is taken into account. Also, to construct the dataset, SQuAD and monSenseQA have been used, and a total of 39 datasets are to be included in CTGA. Finally, Bonito on PubMedQA reaches the peak performance of 47.1 F1 points after 10,000 steps.
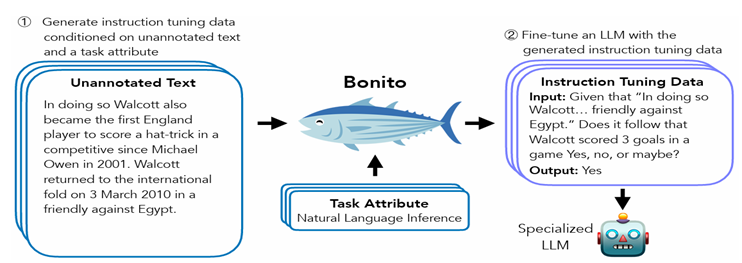
In conclusion, Bonito, an open-source model for conditional task generation that converts unannotated texts into instruction-tuning datasets, successfully shows that training with synthetic instruction tuning with datasets in specialized domains is a strong alternative to self-supervision. However, it’s crucial to note that when dealing with limited unannotated text, adapting the target language model may lead to a decline in performance.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Researchers at Brown University Introduce Bonito: An Open-Source AI Model for Conditional Task Generation to Convert Unannotated Texts into Instruction Tuning Datasets appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]