


AI researchers aim to create models that can handle human language and code. These advanced models are designed to break down linguistic barriers and facilitate more intuitive interactions between humans and machines, catering to a global audience and a wide array of programming tasks.
One significant hurdle in this journey has been developing a model that can seamlessly transition between understanding multiple natural languages and deciphering the structured logic of programming languages. This challenge entails the acquisition of linguistic nuances and cultural context and the intricacies of code syntax and semantics, making it a multifaceted and daunting task.
Historically, approaches to tackle this issue have involved training expansive models on diverse datasets that include many languages and code snippets. The aim has been to create a balance between the volume of training data and the model’s capacity, ensuring that the model learns effectively without favoring one language domain over another. However, these efforts have often needed to be improved in the breadth of languages covered or in maintaining consistent performance across different tasks.
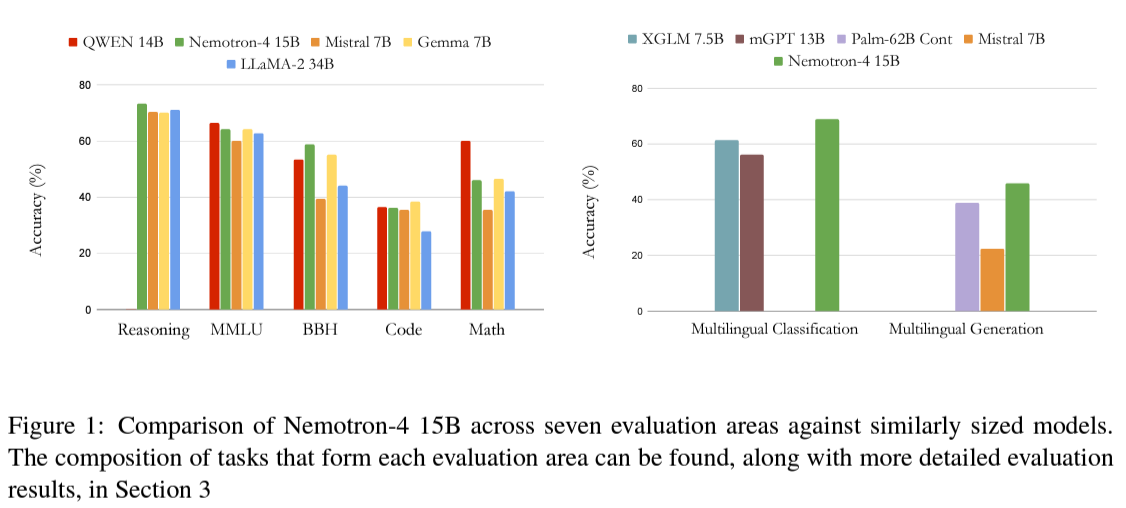
NVIDIA, a company renowned for its contributions to artificial intelligence and computing, has introduced a groundbreaking solution to these challenges with its Nemotron-4 15B model. This 15-billion-parameter, large multilingual language model has been trained on an unprecedented 8 trillion tokens, covering English, a wide range of natural languages, and programming languages. The scale and diversity of the training set have propelled Nemotron-4 15B to the forefront of the field, enabling it to outshine similarly sized models in terms of multilingual capabilities and even surpass larger, specialized models.
The innovation behind Nemotron-4 15B extends into its meticulous training methodology. The model employs a standard decoder-only Transformer architecture, optimized with Rotary Position embedding and a SentencePiece tokenizer to enhance its understanding and generation capabilities. This architectural choice, combined with the strategic selection and processing of the training data, ensures that Nemotron-4 15B not only learns from a vast array of sources but does so efficiently, minimizing redundancy and maximizing coverage of low-resource languages.
The performance of Nemotron-4 15B is a testament to the effectiveness of NVIDIA’s approach. In comprehensive evaluations covering English, coding tasks, and multilingual benchmarks, Nemotron-4 15B demonstrated exceptional proficiency. It achieved high downstream accuracies across a wide range of functions, significantly outperforming the LLaMA-2 34B model, which has over twice the number of parameters in multilingual capabilities. Specifically, in coding tasks, Nemotron-4 15B exhibited better average accuracy than models specialized in code, such as Starcoder, and showed superior performance in low-resource programming languages. Moreover, Nemotron-4 15B set new records in multilingual evaluations, achieving almost a 12% improvement in the four-shot setting of the XCOPA benchmark over other large language models.
This unparalleled performance illustrates the model’s advanced understanding and generation capabilities across domains. It solidifies its position as the leading model in its class for both general-purpose language understanding and specialized tasks. NVIDIA’s Nemotron-4 15B represents a significant leap forward in developing AI models. Nemotron-4 15B paves the way for a new era of AI applications by mastering the dual challenges of multilingual text comprehension and programming language interpretation. These include seamless global communication, more accessible coding education, and enhanced machine-human interactions across different languages and cultures. The meticulous methodology behind the model’s training and its remarkable performance underscores the potential of large language models to revolutionize our interaction with technology, making it more inclusive and effective globally.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post NVIDIA Researchers Introduce Nemotron-4 15B: A 15B Parameter Large Multilingual Language Model Trained on 8T Text Tokens appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]