


From producing writing that resembles that of a human being to comprehending subtleties of language, Large Language Models (LLMs) have played a key role in attaining state-of-the-art performance in various Natural Language Processing (NLP) applications. However, their efficacy wanes when processing texts exceeding their training length, limiting their utility for comprehensive document analysis or extended dialogues.
Previous work has focused on expanding the base frequency of RoPE or PI to increase the supported context length of LLMs. The industry has predominantly relied on developing the base frequency of RoPE or PI due to high training costs and incompatibilities with technologies like Flash Attention.
A team of researchers from The University of Hong Kong, Alibaba Group, and Fudan University has devised a novel framework known as Dual Chunk Attention (DCA), which ingeniously extends the operational capacity of LLMs to process significantly longer text sequences without necessitating additional training. This breakthrough circumvents the traditional barriers associated with the extensive context handling of LLMs, such as prohibitive computational costs and the logistical complexities of training on large datasets.
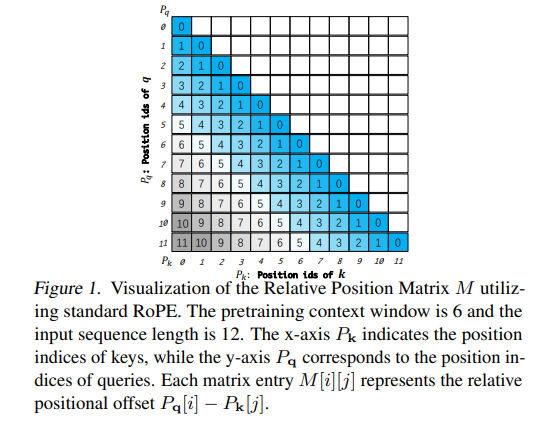
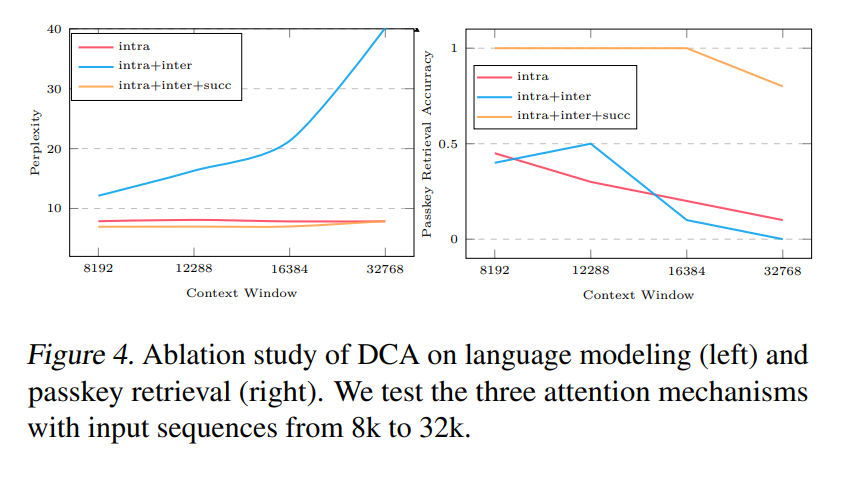
DCA consists of three attention mechanisms: intra-chunk, inter-chunk, and successive-chunk. Intra-chunk attention calculates the inner product of queries and keys within the same chunk. Inter-chunk attention aggregates information from different chunks by adjusting the position indices for queries and keys. Successive-chunk attention is a special case of inter-chunk attention that maintains the locality of neighboring tokens. The relative position matrix M is computed using the position indices and is used to calculate the attention scores. Softmax normalization is applied to the attention scores to obtain the final probabilities.
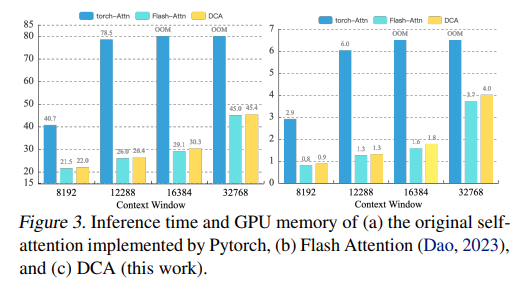
One of the standout features of DCA is its integration with Flash Attention, a technology that enhances the model’s memory efficiency and processing speed. This synergy between DCA and Flash Attention allows for an optimal balance between computational resources and performance, enabling the model to handle long text sequences in a fraction of the time required by traditional methods.
The efficacy of DCA is underscored by its remarkable performance in practical tasks requiring extensive context understanding. The framework demonstrated its prowess by achieving performance levels comparable to or surpassing fine-tuned models on long-context benchmarks. Specifically, when equipped with DCA, a 70B LLM model achieved a 94% performance rate of GPT-3.5-turbo-16k on tasks that necessitated processing texts over 100k tokens long. This level of performance, achieved without the need for additional training, represents a significant advancement in the capabilities of LLMs, opening new avenues for their application in areas that demand detailed and comprehensive text analysis.
In conclusion, the introduction of DCA by the researchers heralds a new era in the capabilities of LLMs. By enabling efficient processing of extended text sequences without further training, DCA not only overcomes a significant limitation of current models but also expands the horizons for their application across various domains. This technological leap forward offers promising prospects for developing more sophisticated and versatile NLP tools capable of tackling the increasingly complex demands of processing and generating human language. With DCA, the potential for LLMs to revolutionize fields such as automated content creation, in-depth document analysis, and interactive AI systems becomes ever more tangible, marking a pivotal advancement in the ongoing evolution of NLP technologies.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Efficiently Processing Extended Contexts in Large Language Models: Dual Chunk Attention for Training-Free Long-Context Support appeared first on MarkTechPost.
#AIShorts #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]