


Engineering effective prompts for LLMs is crucial yet challenging due to their sensitivity to prompts and the ambiguity of task instructions. Recent studies propose using meta-prompts that learn from past trials to suggest improved prompts automatically. However, evaluating prompt effectiveness requires high-quality benchmarks, often scarce and expensive. While LLMs excel in generating diverse datasets and refining prompts, their accuracy hinges on correctly interpreting user intentions. Despite advancements, prompt sensitivity remains a hurdle, especially in proprietary models where version changes can alter behavior significantly. Balancing prompt optimization with practical constraints is essential for real-world LLM applications.
A team of researchers has devised Intent-based Prompt Calibration (IPC), a system to fine-tune prompts based on user intention using synthetic examples. It iteratively constructs a dataset of challenging cases and adjusts the prompt accordingly, tailored to real-world scenarios like moderation. Incorporating a prompt ranker extends optimization to new generative tasks with minimal annotation. This modular approach allows components to be used independently, like synthetic data generation or prompt distillation. Compared to prior methods, IPC achieves superior results with minimal data and iterations, reducing overall optimization efforts and costs and making it adaptable to diverse production tasks.
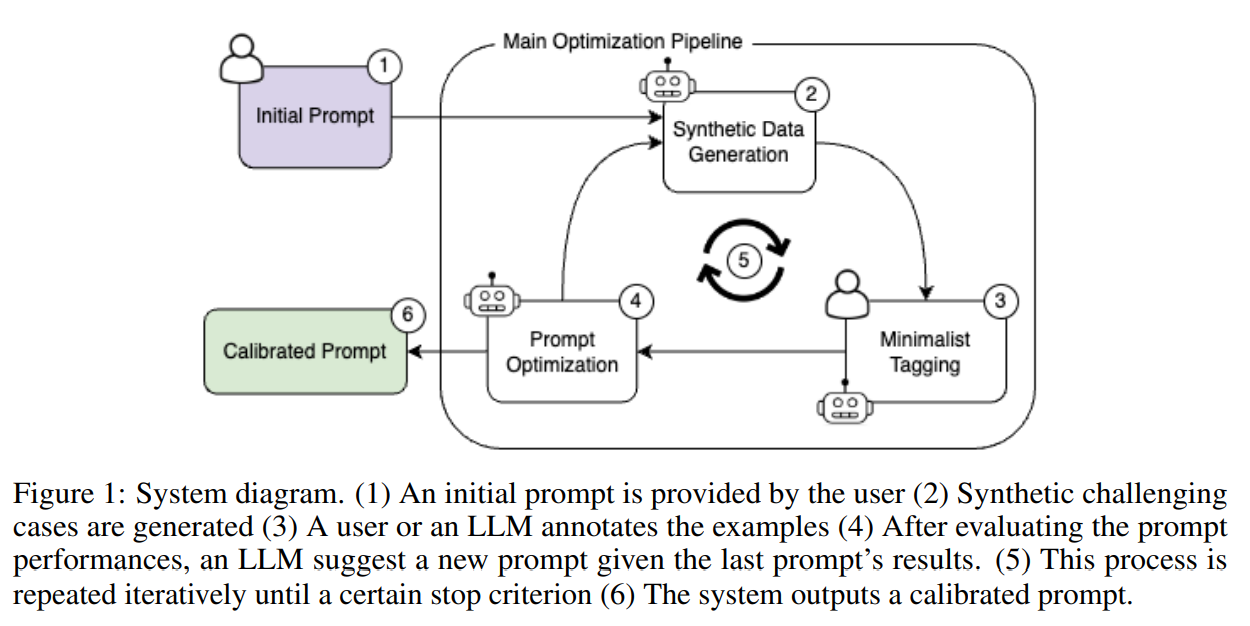
The system begins with an initial prompt and task description. Users may provide examples in a few-shot setting. Through iterative calibration, the system suggests challenging boundary samples, evaluates prompt performance and suggests new prompts based on past iterations. It’s optimized for classification tasks, focusing on accuracy and error analysis. It splits optimization into two parts for generative tasks: ranking calibration and prompt refinement. Meta-prompts guide sample generation, analysis, and prompt generation. The system architecture includes dataset management, estimation, evaluation, and optimization components. Estimators support various tasks like human annotation and LLM estimation. The optimizer manages the iterative process until convergence or usage limit.
Several methods tackle prompt optimization. One common approach optimizes task-specific embeddings, continuously or discretely, necessitating LLM access. Reinforcement learning is an alternative, requiring token probability or extensive training data. Recent methods use LLMs for prompt optimization, applicable even with limited access. However, evaluating generated prompts without valid benchmarks poses challenges. Synthetic data generated by LLMs proves effective for various tasks, offering cost savings and aiding low-resource scenarios. Curriculum learning, inspired by organizing training data progressively, enhances performance. The system iteratively refines prompts, akin to curriculum learning, generating challenging cases to align with user intent efficiently.
The method of automatic prompt engineering using a calibration process and synthetic data generation demonstrated better performance than state-of-the-art methods, even with a limited number of annotated samples. The system’s modular approach allows for easy adaptation to other tasks, making it a flexible and versatile solution. Using synthetic data produced by LLMs proved highly effective in optimizing prompt performance and achieving higher-quality results. The calibration process successfully captured the subtle details and nuances of the ground truth prompt, outperforming other tested methods for prompt accuracy and capturing user intent. The generated synthetic data showed a more balanced distribution and reduced bias compared to real data, leading to improved performance in sentiment classification and other tasks.
In conclusion, the IPC system automates prompt engineering by combining synthetic data generation and prompt optimization modules, iteratively refining prompts using prompting LLMs until convergence. It proves effective in tasks like moderation and generation, outperforming other methods. The system’s modular design allows for easy adaptation and addition of components, making it versatile for various tasks. Future work includes expanding into multi-modality and in-context learning and optimizing the meta-prompts further. Additionally, synthetic data addresses data bias and imbalance issues, resulting in more balanced datasets and improved task performance.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Automated Prompt Engineering: Leveraging Synthetic Data and Meta-Prompts for Enhanced LLM Performance appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]