


Developing large language models (LLMs) in artificial intelligence represents a significant leap forward. These models underpin many of today’s advanced natural language processing tasks and have become indispensable tools for understanding and generating human language. However, these models’ computational and memory demands, especially during inference with long sequences, pose substantial challenges.
The core challenge in deploying LLMs efficiently lies in the self-attention mechanism, which significantly impacts performance due to its memory-intensive operations. The mechanism’s memory complexity grows with the context length, leading to increased inference costs and limitations in system throughput. This challenge is exacerbated by the trend toward models that process increasingly longer sequences, highlighting the need for optimized solutions.
Prior attempts to address the inefficiencies of LLM inference have explored various optimization strategies. However, these solutions often must balance computational efficiency and memory usage, especially when handling long sequences. The limitations of existing approaches underscore the necessity for innovative solutions that can navigate the complexities of optimizing LLM inference.
The research presents ChunkAttention, a groundbreaking method developed by a team at Microsoft designed to enhance the efficiency of the self-attention mechanism in LLMs. By employing a prefix-aware key/value (KV) cache system and a novel two-phase partition algorithm, ChunkAttention optimizes memory utilization and accelerates the self-attention process. This approach is particularly effective for applications utilizing LLMs with shared system prompts, a common feature in many LLM deployments.
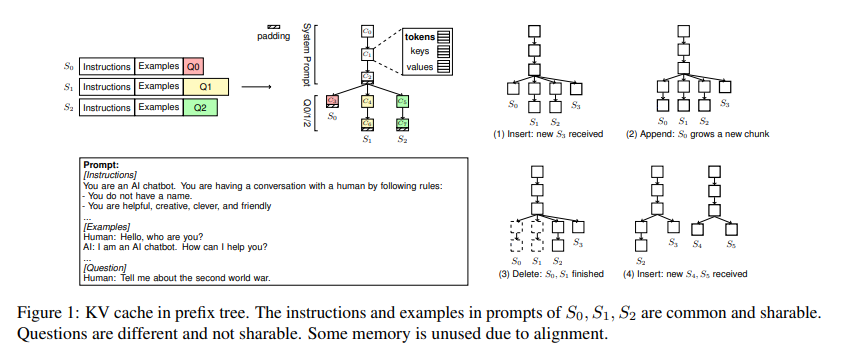
At the heart of ChunkAttention’s innovation is its management of the KV cache. The method organizes key/value tensors into smaller, manageable chunks and structures them within an auxiliary prefix tree. This organization allows for the dynamic sharing and efficient use of these tensors across multiple requests, significantly reducing memory waste. Moreover, by batching operations for sequences with matching prompt prefixes, ChunkAttention enhances computational speed and efficiency.
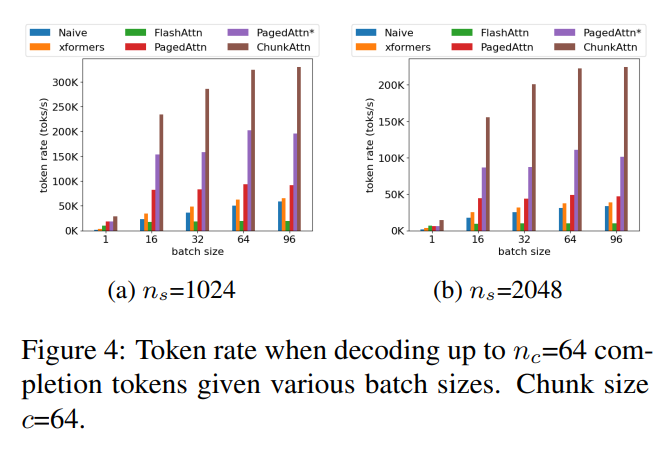
The effectiveness of ChunkAttention is demonstrated through rigorous empirical testing, which reveals a substantial improvement in inference speed. The method achieves a 3.2 to 4.8 times speedup compared to existing state-of-the-art implementations for sequences with shared system prompts. These results testify to the method’s ability to address the dual challenges of memory efficiency and computational speed in LLM inference.
In conclusion, the introduction of ChunkAttention marks a significant advancement in artificial intelligence, particularly in optimizing the inference processes of large language models. This research paves the way for more effective and efficient deployment of LLMs across a wide range of applications by addressing critical inefficiencies in the self-attention mechanism. The study highlights the potential of innovative optimization strategies and sets a new benchmark for future research in the field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post This Machine Learning Paper from Microsoft Proposes ChunkAttention: A Novel Self-Attention Module to Efficiently Manage KV Cache and Accelerate the Self-Attention Kernel for LLMs Inference appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]