


The exploration of large language models (LLMs) has significantly advanced the capabilities of machines in understanding and generating human-like text. Scaled from millions to billions of parameters, these models represent a leap forward in artificial intelligence research, offering profound insights and applications in various domains. However, evaluating these sophisticated models has predominantly relied on methods that measure the likelihood of a correct response through output probabilities. While computationally efficient, this conventional approach often needs to mirror the complexity of real-world tasks where models are expected to generate full-fledged responses to open-ended questions.
Recent investigations have pointed out the inherent limitations of such probability-based evaluation techniques. Earlier methods like label-based and sequence-based predictions assess an LLM’s performance by calculating the probability of either the next token or a sequence of tokens being correct. This approach, though widely used, needs to accurately capture the essence of LLMs’ capabilities, especially in scenarios that demand creative and context-aware generation of text. The crux of the issue lies in the disconnection between what these models are capable of and how their performance is measured.
Researchers from Mohamed bin Zayed University of Artificial Intelligence and Monash University have proposed a new methodology focusing on generation-based predictions. Unlike its predecessors, this method evaluates LLMs based on their ability to generate complete and coherent responses to prompts. This shift towards generation-based evaluation represents a more realistic assessment of LLMs’ performance in practical applications. Researchers conducted extensive experiments across multiple benchmarks to compare the effectiveness of generation-based evaluations against traditional probability-based methods. These experiments highlighted the discrepancies between the two approaches and demonstrated the superiority of generation-based predictions in evaluating LLMs’ real-world utility.
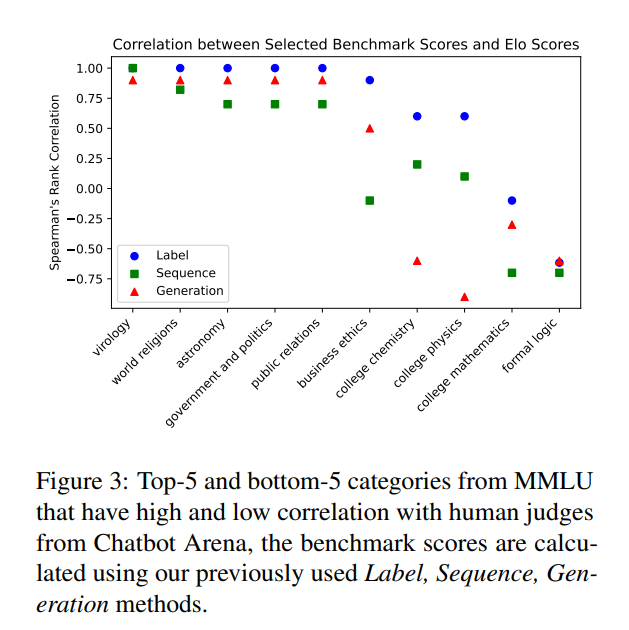
Generation-based evaluations consistently provided a more accurate reflection of an LLM’s capabilities, uncovering nuances previously overlooked by probability-based methods. For instance, while traditional methods might deem an LLM highly efficient based on its probability scores, generation-based evaluations could reveal limitations in the model’s ability to generate contextually relevant and coherent responses. This discrepancy calls into question the reliability of current evaluation frameworks and underscores the need for methodologies that better align with the practical applications of LLMs.

In conclusion, the study brings to light several key insights:
- Probability-based evaluation methods may only partially capture the capabilities of LLMs, particularly in real-world applications.
- Generation-based predictions offer a more accurate and realistic assessment of LLMs, aligning closely with their intended use cases.
- There is a pressing need to reevaluate and evolve the current LLM evaluation paradigms to ensure they reflect these models’ true potential and limitations.
These findings challenge the existing evaluation standards and pave the way for future research to develop more relevant and accurate methods for the performance assessment of LLMs. By embracing a more nuanced evaluation framework, the research community can better understand and leverage the capabilities of LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Redefining Evaluation: Towards Generation-Based Metrics for Assessing Large Language Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]