


There has been notable progress in Vision-Language tasks, with models like CLIP showing impressive performance in various tasks. While these models excel at recognizing objects, they need help composing known concepts in novel ways due to text representations that appear indifferent to word order. Even large-scale models like GPT-4V have yet to show evidence of successfully identifying compositions, highlighting a limitation in Vision-Language modeling.
Existing methods like NegCLIP and REPLACE aim to enhance compositional capabilities in Vision-Language Models (VLMs). However, they often trade off performance in object-centric recognition tasks like ImageNet. NegCLIP shows improved compositionality on SugarCrepe benchmarks but at the expense of ImageNet accuracy. REPLACE enhances SugarCrepe scores but significantly reduces ImageNet performance, indicating a challenge in balancing compositional abilities with standard recognition tasks.
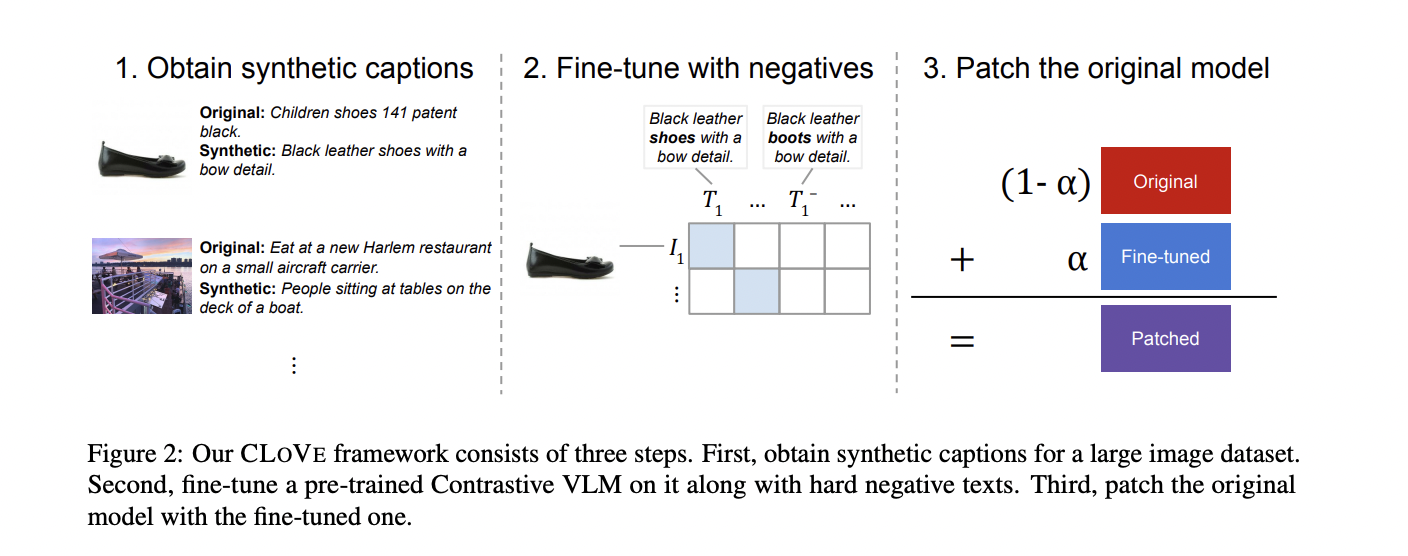
Researchers from the University of Michigan – Ann Arbor and Netflix have proposed a new method, CLOVE, that enhances the compositional language encoding in existing two-tower models while maintaining performance on standard benchmarks. It achieves this through three key contributions: leveraging data curation to impact compositional knowledge handling, incorporating training with hard negatives for additional improvements, and utilizing model patching to preserve performance on previous tasks. CLOVE combines these ideas to enhance compositionality significantly over contrastively pre-trained vision-language models.
CLOVE enhances compositionality in VLMs by utilizing synthetic data generation to expand training data, incorporating randomly generated hard text negatives for improved model understanding, and employing model patching to balance compositional gains with maintaining performance on previous tasks. This approach enables the fine-tuned model to retain enhanced compositionality while recovering performance on functions supported by the pre-trained model, effectively advancing VLM capabilities without sacrificing overall performance.
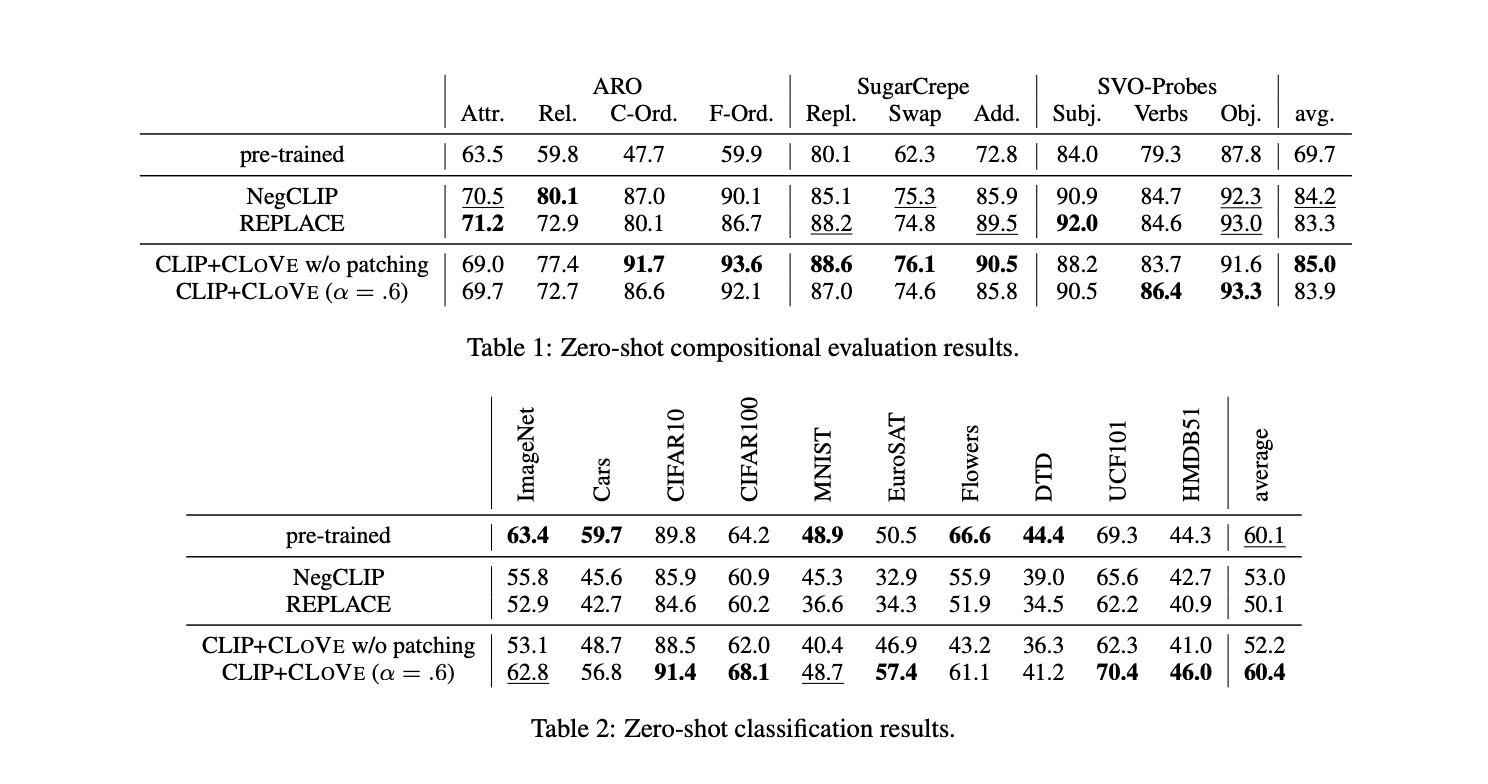
CLIP+CLOVE framework significantly improves compositionality over pre-trained CLIP while maintaining ImageNet performance within 1%. In comparison, NegCLIP and REPLACE show diminished performance in object recognition benchmarks. CLIP+CLOVE outperforms other methods across compositionality benchmarks ARO, SugarCrepe, and SVO-Probes. CLIP+CLOVE achieves higher Recall@5 scores than NegCLIP and REPLACE, indicating its superior text representation capabilities in zero-shot text-to-image and image-to-text retrieval tasks.
In conclusion, researchers from the University of Michigan – Ann Arbor and Netflix have presented CLOVE, a framework enhancing compositionality in pre-trained Contrastive VLMs while preserving performance on other tasks. By fine-tuning models with hard negative texts and leveraging synthetically captioned images, CLOVE achieves significant improvements. Experimental results demonstrate its effectiveness across various benchmarks, underscoring the importance of data quality, utilization of hard negatives, and model patching for enhancing VLMs’ capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post This AI Paper from the University of Michigan and Netflix Proposes CLoVe: A Machine Learning Framework to Improve the Compositionality of Pre-Trained Contrastive Vision-Language Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]