


Large Language Models (LLMs) have emerged as a powerful ally for developers, promising to revolutionize how coding tasks are approached. By serving as intelligent assistants, LLMs have the potential to streamline various aspects of the development process, from code generation to bug fixing, making the coder’s work not only faster but also more accurate.
One of the crucial challenges is the effective integration of LLMs within Integrated Development Environments (IDEs) to maximize their potential benefits. While LLMs offer a significant promise in assisting with coding tasks, their deployment is challenging. A primary concern is ensuring that these models adapt optimally to the diverse and complex nature of software development tasks, which requires a fine-tuning process tailored to each project’s specific needs and contexts.
Current methodologies for integrating LLMs into IDEs often rely on general-purpose models that, while powerful, may only deliver optimal performance across some coding scenarios. Applying LLMs to software development requires careful consideration of their performance across specific applications such as code generation, summarization, and bug detection. Tools like CodeXGLUE and datasets like HumanEval have been instrumental in benchmarking LLM capabilities in these domains. These platforms assess the functional correctness of code generated by LLMs and emphasize the importance of aligning LLMs with the specific needs of software engineering tasks.
Researchers from Microsoft have introduced Copilot, a novel evaluation harness specifically designed for assessing LLM-guided programming within IDEs. Copilot focuses on evaluating the performance of LLMs across a range of programming scenarios. Establishing a comprehensive set of metrics aims to provide a more detailed and accurate assessment of how well LLMs can support software development tasks.
The Copilot Evaluation Harness collects data from public GitHub repositories in JavaScript, TypeScript, Python, Java, C/C++, and C#. This data collection process is supported by a build agent capable of executing various build and test strategies, which is crucial for preparing a comprehensive test dataset. During experiments, the harness evaluates LLMs across five key software development tasks, considering factors like syntax correctness, success in bug fixing, and documentation generation. Each task is meticulously designed to mirror actual development scenarios, enabling the researchers to assess the LLMs’ adaptability, accuracy, and efficiency in a controlled yet diverse testing environment. Regarding bug fixing, the bug Fixing metric generates test cases based on static analysis tool warnings and errors.
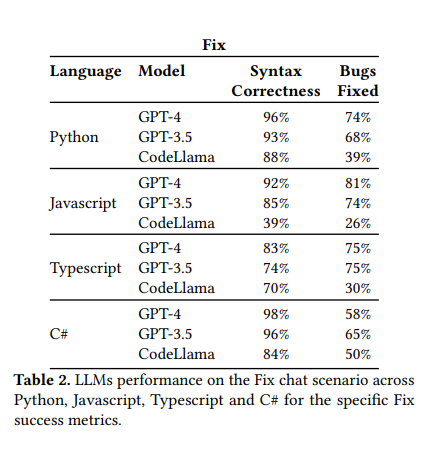
The study reveals that while LLMs like GPT-3.5 and GPT-4 show promising capabilities in documentation generation and bug fixing, there are marked differences in performance across various programming languages and tasks. In documentation generation across different programming languages, GPT-4 achieved syntax and format correctness scores as high as 100% in Python and nearly 96% in Typescript, outperforming GPT-3.5 and CodeLlama. In bug-fixing tasks, GPT-4 showed a notable performance with a syntax correctness score of 96% in Python and a bug-fixed rate of 74%, indicating its superior ability to address coding errors compared to its predecessors and alternatives. These quantitative results underscore the potential of advanced LLMs in enhancing software development efficiency and accuracy.
In conclusion, the proposed research introduces the Copilot Evaluation harness, emphasizing five key evaluation metrics for code generation: method generation, test generation, docstring generation, bug fixing, and workspace understanding. This evaluation harness aims to validate the quality of LLM-generated code and provide developers with a comprehensive evaluation suite to optimize the integration of LLMs into their coding workflows. Copilot can also be used for cost optimizations by identifying when a more budget-friendly LLM model can be used for certain tasks while more complex tasks can be assigned to more powerful LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram ChannelYou may also like our FREE AI Courses….
The post Microsoft AI Proposes Metrics for Assessing the Effectiveness of Large Language Models in Software Engineering Tasks appeared first on MarkTechPost.
#AIShorts #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]