


The ability to predict outcomes from a myriad of parameters has traditionally been anchored in specific, narrowly focused regression methods. While effective within its domain, this specialized approach often needs to be revised when confronted with the complexity and diversity inherent in real-world experiments. The challenge, therefore, lies not merely in prediction but in crafting a tool versatile enough to navigate across the broad spectrum of tasks, each with its distinct parameters and outcomes, without necessitating task-specific tailoring.
Regression tools have been developed to address this predictive task, leveraging statistical techniques and neural networks to estimate outcomes based on input parameters. These tools, including Gaussian Processes, tree-based methods, and neural networks, have shown promise in their respective fields. They encounter limitations when generalizing across diverse experiments or adapting to scenarios requiring multi-task learning, often necessitating intricate feature engineering or complex normalization processes to function effectively.
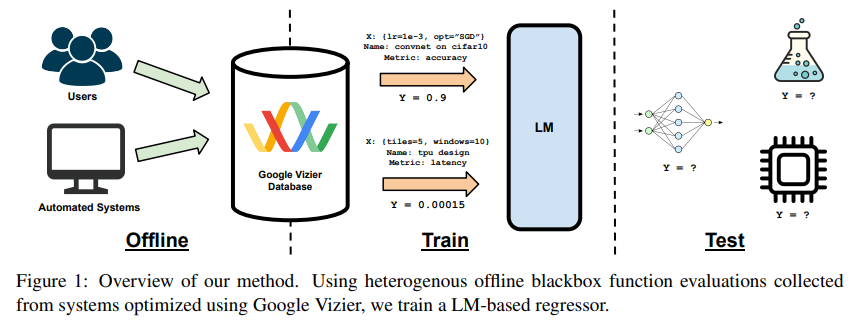
OmniPred emerges as a groundbreaking framework from a collaborative effort by researchers at Google DeepMind, Carnegie Mellon University, and Google. This innovative framework reconceptualizes the role of language models, transforming them into universal end-to-end regressors. OmniPred’s genius lies in its use of textual representations of mathematical parameters and values, enabling it to predict metrics adeptly across various experimental designs. Drawing upon the vast dataset of Google Vizier, OmniPred demonstrates an exceptional capacity for precise numerical regression, significantly outperforming traditional regression models in versatility and accuracy.
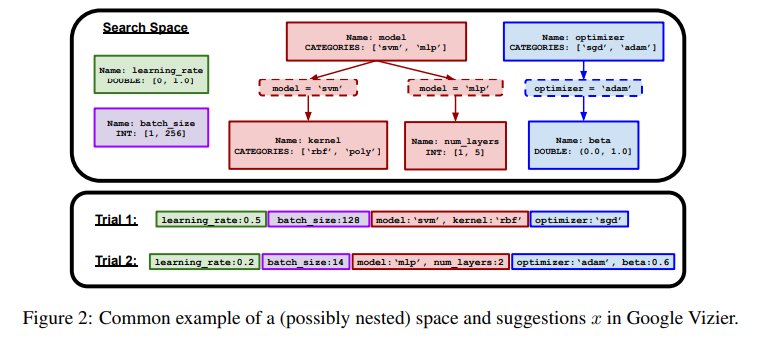
At the core of OmniPred is a simple yet scalable metric prediction framework that eschews constraint-dependent representations in favor of generalizable textual inputs. This approach allows OmniPred to navigate the complexities of experimental design data with remarkable accuracy. The framework’s prowess is further enhanced through multi-task learning, enabling it to surpass the capabilities of conventional regression models by leveraging the nuanced understanding afforded by textual and token-based representations.
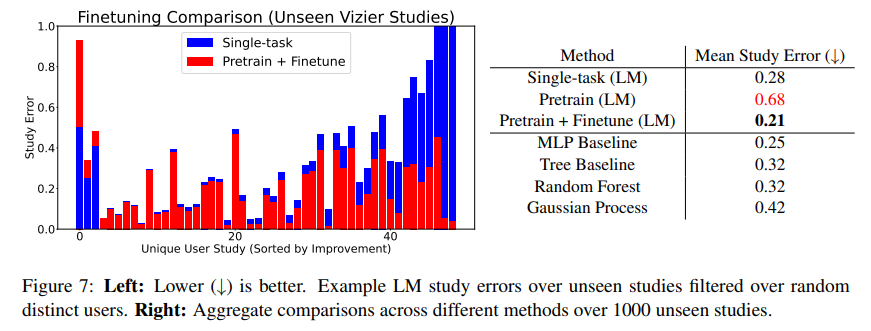
The framework’s ability to process textual representations and scalability sets a new standard for metric prediction. Through rigorous experimentation using Google Vizier’s dataset, OmniPred demonstrated a significant improvement over baseline models and highlighted the advantage of multi-task learning and the potential for fine-tuning to enhance accuracy on unseen tasks.
In synthesizing these findings, OmniPred stands as the potential of integrating language models into the fabric of experimental design, offering:
- A revolutionary approach to regression, leveraging the nuanced capabilities of language models for universal metric prediction.
- Demonstrated superiority over traditional regression models, with significant improvements in accuracy and adaptability across diverse tasks.
- The ability to transcend the limitations of fixed-input representations, offering a flexible and scalable solution for experimental design.
- A framework that embraces multi-task learning, showcasing the benefits of transfer learning even in the face of unseen tasks, further augmented by the potential for localized fine-tuning.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Meet OmniPred: A Machine Learning Framework to Transform Experimental Design with Universal Regression Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]