


Last month, Ai Bloks announced the open-source launch of its development framework, llmware, for building enterprise-grade LLM-based workflow applications. Today, Ai Bloks takes another big step on the journey of delivering a next-generation RAG framework with the release of the DRAGON (Delivering RAG on …) series of 7B parameter LLMs, designed for business workflows and fine-tuned with the specific objective of fact-based question-answering for complex business and legal documents.
As more enterprises look to deploy scalable RAG systems using their own private information, there is a growing recognition of several needs:
- Unified framework that integrates LLM models with a set of surrounding workflow capabilities (e.g., document parsing, embedding, prompt management, source verification, audit tracking);
- High-quality, smaller, specialized LLMs that have been optimized for fact-based question-answering and enterprise workflows and
- Open Source, Cost-effective, Private deployment with flexibility and options for customization.
To meet these needs, LLMWare is launching seven DRAGON models available in open source in its Hugging Face repository, all of which have been extensively fine-tuned for RAG and built on top of leading foundation models with strong production-grade readiness for enterprise RAG workflows.
All of the DRAGON models have been evaluated using the llmware rag-instruct-benchmark with the full test results and methodology provided with the models in the repository. Each of the DRAGON models achieve accuracy in the mid-to-high 90s on a diverse set of 100 core test questions, with strong grounding to avoid hallucinations and to identify when a question cannot be answered from a passage (e.g., ‘not found’ classification).
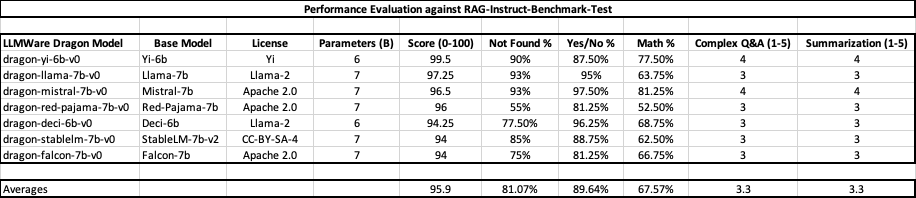
The DRAGON model family joins two other LLMWare RAG model collections: BLING and Industry-BERT. The BLING models are no-GPU required RAG-specialized smaller LLM models (1B – 3B) that can run on a developer’s laptop. Since the training methodology is very similar, the intent is that a developer can start with a local BLING model, running on their laptop, and then seamlessly drop-in a DRAGON model for higher performance in production. DRAGON models have all been designed for private deployment on a single enterprise-grade GPU server, so that enterprises can deploy an end-to-end RAG system, securely and privately in their own security zone.
This suite of open-source RAG-specialized models, combined with the core LLMWare development framework and out-of-the-box integration with open-source private-cloud instances of Milvus and Mongo DB, provide an end-to-end solution for RAG. With a few lines of code, a developer can automate the ingestion and parsing of thousands of documents, attach embedding vectors, execute state-of-the-art LLM-based generative inferences, and run evidence and source verification, all in a private cloud, and in some cases, even from a single developer’s laptop.
According to Ai Bloks CEO Darren Oberst, “Our belief is that LLMs enable a new automation workflow in the enterprise, and our vision for LLMWare is to bring together the specialized models, the data pipeline, and all of the enabling components in a unified framework in open source to enable enterprises to rapidly customize and deploy LLM-based automation at scale.”
For more information, please see the llmware github repository at www.github.com/llmware-ai/llmware.git.
For direct access to the models, please see the llmware Huggingface organization page at www.huggingface.co/llmware.
Thanks to AI Bloks for the thought leadership/ Educational article. AI Bloks has supported us in this content/article.
The post LLMWare Launches RAG-Specialized 7B Parameter LLMs: Production-Grade Fine-Tuned Models for Enterprise Workflows Involving Complex Business Documents appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Promote #Sponsored #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]