


Mixture-of-experts (MoE) models have revolutionized artificial intelligence by enabling the dynamic allocation of tasks to specialized components within larger models. However, a major challenge in adopting MoE models is their deployment in environments with limited computational resources. The vast size of these models often surpasses the memory capabilities of standard GPUs, restricting their use in low-resource settings. This limitation hampers the models’ effectiveness and challenges researchers and developers aiming to leverage MoE models for complex computational tasks without access to high-end hardware.
Existing methods for deploying MoE models in constrained environments typically involve offloading part of the model computation to the CPU. While this approach helps manage GPU memory limitations, it introduces significant latency due to the slow data transfers between the CPU and GPU. State-of-the-art MoE models also often employ alternative activation functions, such as SiLU, which makes it challenging to apply sparsity-exploiting strategies directly. Pruning channels not close enough to zero could negatively impact the model’s performance, requiring a more sophisticated approach to leverage sparsity.

A team of researchers from the University of Washington has introduced Fiddler, an innovative solution designed to optimize the deployment of MoE models by efficiently orchestrating CPU and GPU resources. Fiddler minimizes the data transfer overhead by executing expert layers on the CPU, reducing the latency associated with moving data between CPU and GPU. This approach addresses the limitations of existing methods and enhances the feasibility of deploying large MoE models in resource-constrained environments.
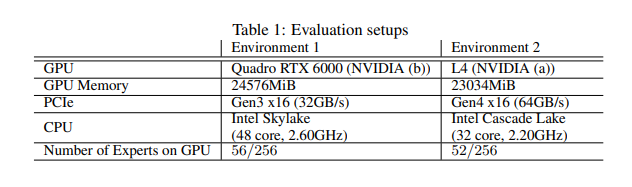
Fiddler distinguishes itself by leveraging the computational capabilities of the CPU for expert layer processing while minimizing the volume of data transferred between the CPU and GPU. This methodology drastically cuts down the latency for CPU-GPU communication, enabling the system to run large MoE models, such as the Mixtral-8x7B with over 90GB of parameters, efficiently on a single GPU with limited memory. Fiddler’s design showcases a significant technical innovation in AI model deployment.
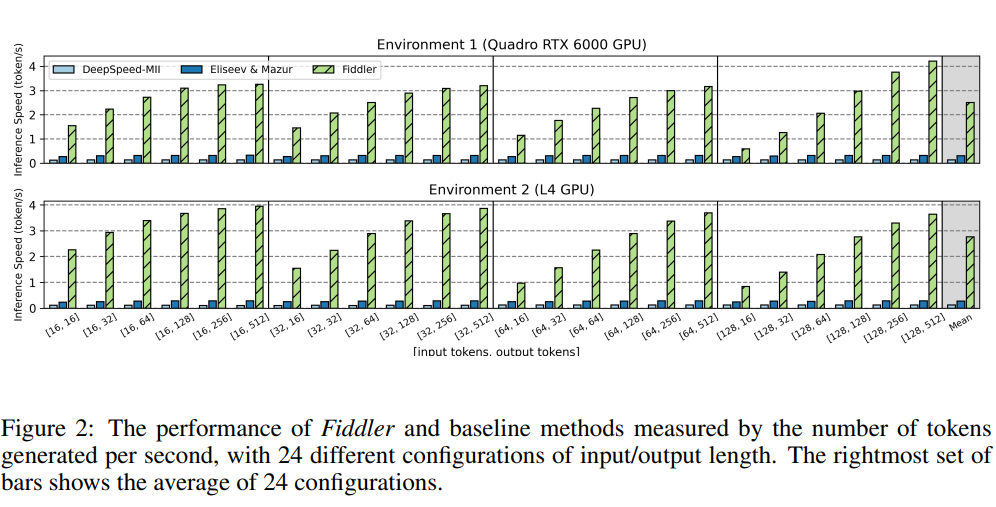
Fiddler’s effectiveness is underscored by its performance metrics, which demonstrate an order of magnitude improvement over traditional offloading methods. The performance is measured by the number of tokens generated per second. Fiddler successfully ran the uncompressed Mixtral-8x7B model in tests, rendering over three tokens per second on a single 24GB GPU. It improves with longer output lengths for the same input length, as the latency of the prefill stage is amortized. On average, Fiddler is faster than Eliseev Mazur by 8.2 times to 10.1 times and quicker than DeepSpeed-MII by 19.4 times to 22.5 times, depending on the environment.
In conclusion, Fiddler represents a significant leap forward in enabling the efficient inference of MoE models in environments with limited computational resources. By ingeniously utilizing CPU and GPU for model inference, Fiddler overcomes the prevalent challenges faced by traditional deployment methods, offering a scalable solution that enhances the accessibility of advanced MoE models. This breakthrough can potentially democratize large-scale AI models, paving the way for broader applications and research in artificial intelligence.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Researchers from the University of Washington Introduce Fiddler: A Resource-Efficient Inference Engine for LLMs with CPU-GPU Orchestration appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]