


Deep reinforcement learning (RL) focuses on agents learning to achieve a goal. These agents are trained using algorithms that balance exploration of the environment with the exploitation of known strategies to maximize cumulative rewards. A critical challenge within deep reinforcement learning is the effective scaling of model parameters. Usually, increasing the size of a neural network leads to better performance in supervised learning tasks. However, this trend must be more straightforward to translate to RL, where larger networks can degrade performance instead of improving it.
Current approaches in deep RL often involve sophisticated techniques like auxiliary losses, distillation, and pre-training to stabilize learning and improve model performance. Despite these efforts, deep RL models underutilize their parameters, leading to suboptimal performance scaling with increased model size. This indicates a gap in our understanding and utilization of neural network capacities within RL.
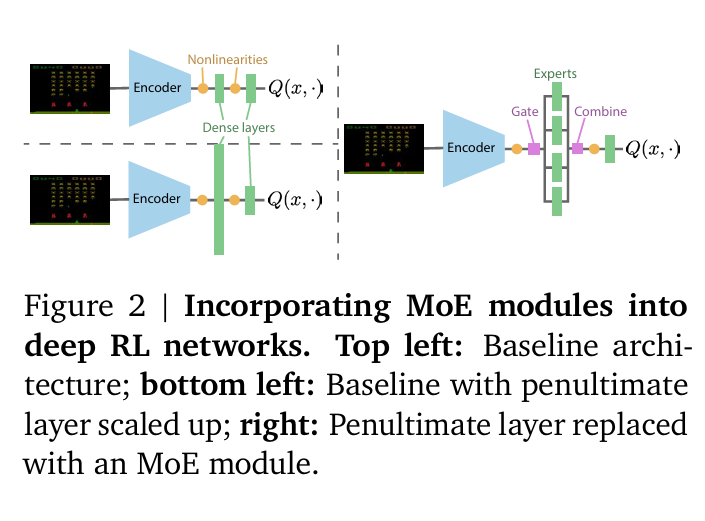
Researchers from DeepMind, Mila – Québec AI Institute, Université de Montréal, along with the University of Oxford and McGill University have introduced the use of Mixture-of-Experts (MoE) modules, specifically Soft MoEs, as a novel approach to address the parameter scaling challenge in deep RL. These modules are integrated into value-based networks, showing promising results by significantly enhancing the models’ parameter efficiency and performance across various sizes and training conditions.
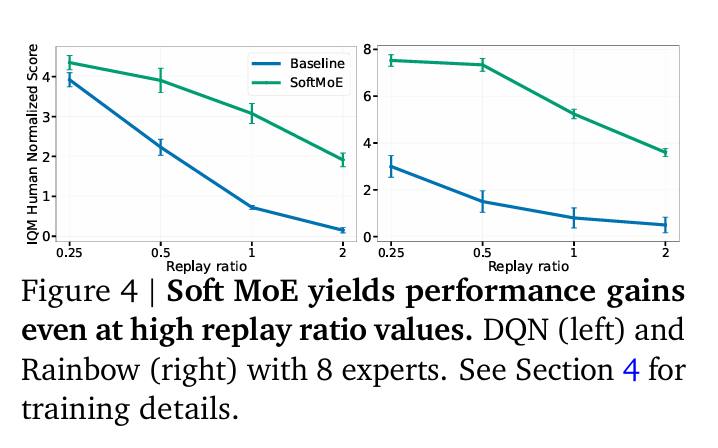
The researchers demonstrate that using MoEs in RL networks leads to more parameter-scalable models, resulting in significant performance improvements across various training regimes and model sizes. Researchers also evaluate the performance of Deep Q-Network (DQN) and Rainbow algorithms with Soft MoE and Top1-MoE on the standard Arcade Learning Environment (ALE) benchmark. The results indicate that incorporating MoEs in deep RL networks can improve performance in different training regimes, including low-data training and offline RL tasks. The experiments utilized NVIDIA Tesla P100 GPUs, and each experiment took an average of 4 days to complete. The research also explores the impact of architectural design choices on the performance of RL agents, highlighting the potential advantages of using MoEs. The implementation of the study is built on the Dopamine library. It follows recommendations for statistically robust performance evaluations, including interquartile mean (IQM) and stratified bootstrap confidence intervals.
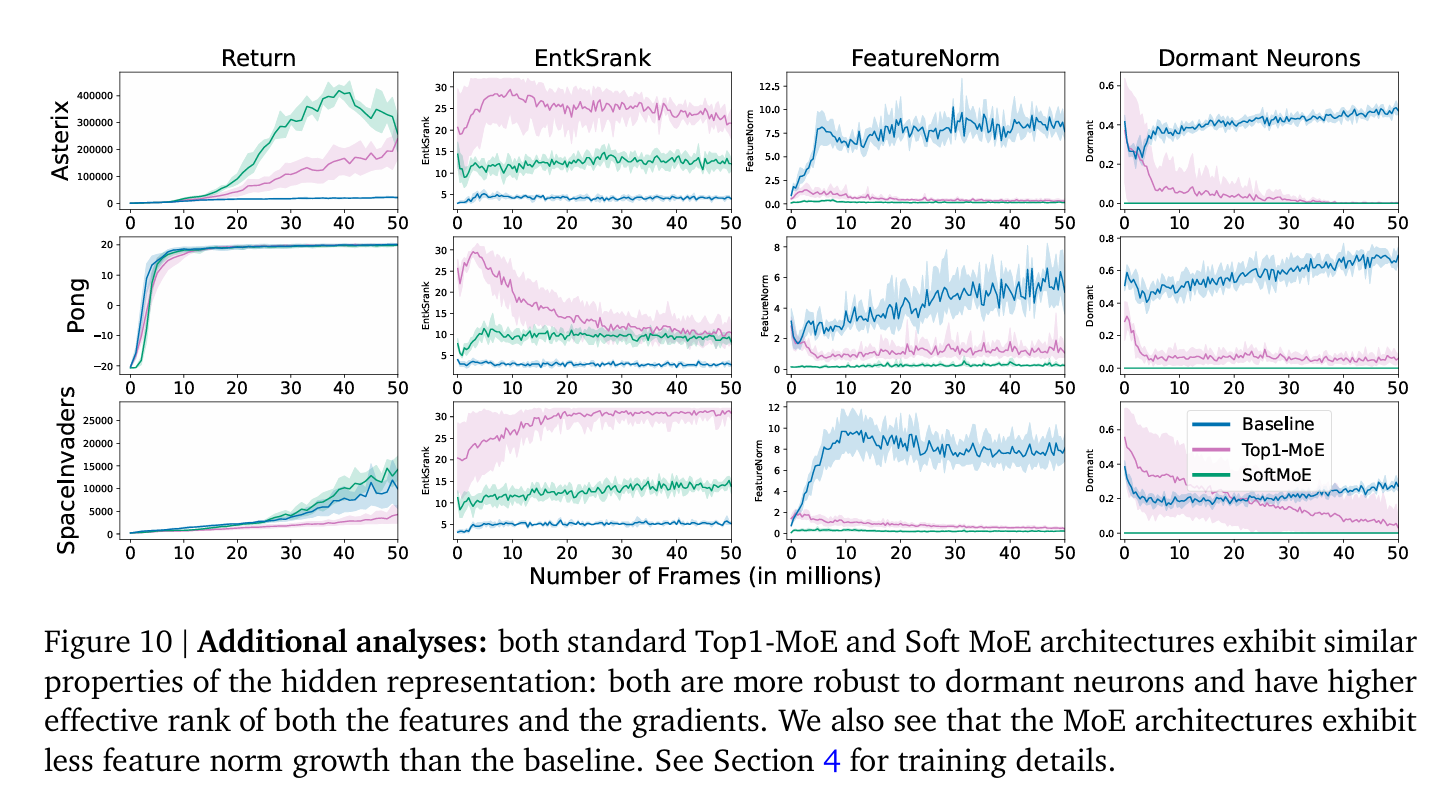
The results illustrate significant performance enhancements. A noteworthy finding is the 20% performance uplift in the Rainbow algorithm with the scaling of experts from 1 to 8, underscoring the scalability and efficiency of Soft MoEs. Evaluations on the ALE benchmark further confirmed the positive impact of MoEs on DQN and Rainbow algorithms. Moreover, Soft MoE emerged as a superior method. It achieved an optimal balance between accuracy and computational cost, showing promise in diverse training settings, including low-data and offline RL tasks. These findings, rooted in robust statistical evaluation methods, underscore the transformative potential of MoEs in enhancing RL agent performance.
The research conclusively shows that MoE modules, especially Soft MoEs, significantly enhance parameter scalability and performance in RL networks. These findings pave the way for developing scaling laws in RL and underscore MoEs’ vital role in advancing RL agent capabilities. Looking ahead, investigating MoEs’ effects across various RL algorithms and combining them with other architectural innovations presents a promising avenue for research. Further exploration into the mechanisms behind MoEs’ success in RL could lead to more sophisticated and efficient RL models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Google DeepMind Researchers Provide Insights into Parameter Scaling for Deep Reinforcement Learning with Mixture-of-Expert Modules appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]