


Mathematical reasoning involves the ability to solve problems and justify solutions logically. This field forms the foundation for developing algorithms, models, and simulations that solve complex real-world problems. Creating LLMs specialized in mathematical reasoning is still challenging due to the scarcity of high-quality, diverse datasets. Most existing datasets need to be bigger to adequately cover the vast space of mathematical problems or are burdened with restrictive licenses that hamper their use in open-source projects.
Existing approaches for enhancing mathematical reasoning in LLMs have primarily relied on closed-source datasets generated by commercial LLMs like GPT-3.5 and GPT-4. – Various techniques such as Chain-of-Thought, Program of Thought, Self-Consistency, and Self-Verification have been used to enhance the mathematical reasoning capabilities of LLMs. Pretraining language models on math-heavy content have resulted in foundation LLMs with stronger mathematical skills. At the same time, dataset-specific training involves instruction finetuning on problem-solution pairs derived from math reasoning datasets.

The research team from NVIDIA has introduced OpenMathInstruct-1, a novel dataset comprising 1.8 million problem-solution pairs to improve mathematical reasoning in LLMs. This dataset stands out due to its open license and the use of Mixtral, an open-source LLM, for data generation, allowing unrestricted use and fostering innovation in the field.
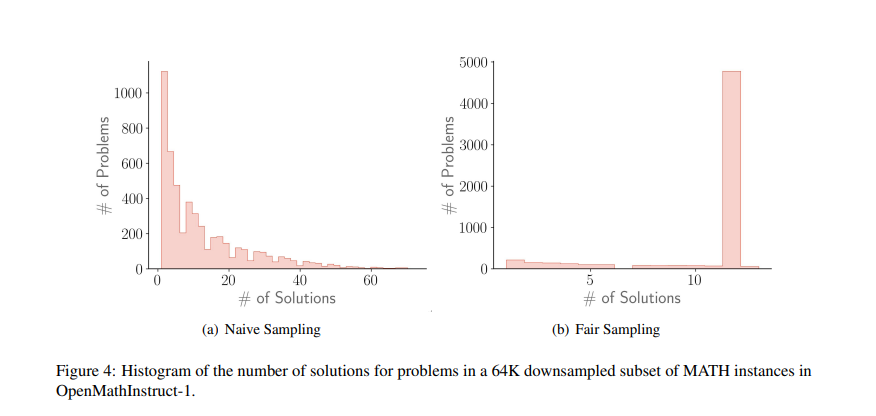
OpenMathInstruct-1 was synthesized using a combination of brute-force scaling and novel prompting strategies with the Mixtral model. To synthesize solutions for GSM8K and MATH benchmarks, the research employed few-shot prompting, incorporating instructions, representative problems, their solutions in code-interpreter format, and a new question from the training set. If the base LLM generated a solution that led to the correct answer, it was included in the finetuning dataset. Solutions were sampled with constraints on token numbers and code blocks, using strategies like default, subject-specific, and masked text solution prompting, with the latter significantly increasing training set coverage by masking numbers in intermediate computations. Post-processing corrected syntactically noisy solutions. Data selection strategies included fair vs. naive downsampling and code-preferential selection, favoring code-based solutions. Models underwent training for four epochs, utilizing the AdamW optimizer, and were evaluated on benchmarks using greedy decoding and self-consistency/majority voting.
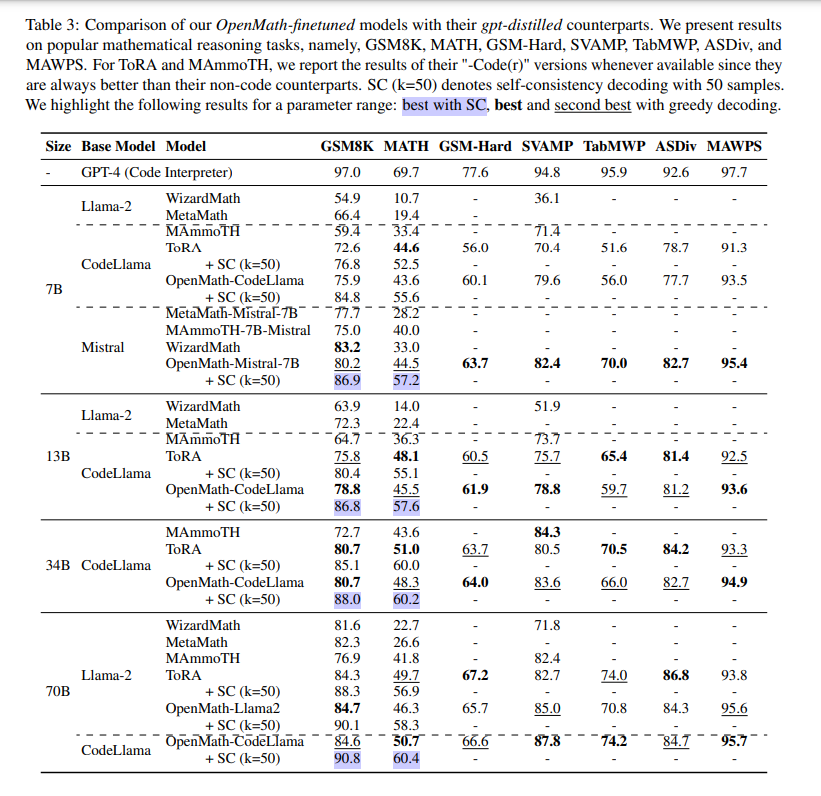
Models finetuned on a mix of 512K downsampled GSM8K and MATH instances, totaling 1.2M, showcased competitive performance against gpt-distilled models across mathematical tasks. For example, when finetuned with OpenMathInstruct-1, the OpenMath-CodeLlama-70B model achieved competitive results, with 84.6% on GSM8K and 50.7% on MATH. Models notably outperformed MAmmoTH and MetaMath, with improvements sustained as model parameters increased. Enhanced by self-consistency decoding, their efficacy varied across tasks, subjects, and difficulty levels within the MATH dataset. Ablation studies highlighted the superiority of fair downsampling over naive approaches and the benefits of increasing dataset size. While code-preferential selection strategies improved greedy decoding, they had mixed effects on self-consistency decoding performance.
OpenMathInstruct-1 marks a significant advancement in the development of LLMs for mathematical reasoning. By offering a large-scale, openly licensed dataset, this work addresses the limitations of existing datasets and sets a new standard for collaborative and accessible research in the field. The success of the OpenMath-CodeLlama-70B model underscores the potential of open-source efforts to achieve breakthroughs in specialized domains like mathematical reasoning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post NVIDIA AI Research Introduce OpenMathInstruct-1: A Math Instruction Tuning Dataset with 1.8M Problem-Solution Pairs appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]