


The quest to enhance Large Language Models (LLMs) has led to a groundbreaking innovation by a team from the Beijing Academy of Artificial Intelligence and Gaoling School of Artificial Intelligence at Renmin University. This research team has introduced a novel methodology known as Extensible Tokenization, aimed at significantly expanding the capacity of LLMs to process and understand extensive contexts without the need to increase the physical size of their context windows. This advancement addresses a critical bottleneck in applying LLMs across various tasks requiring deep comprehension of vast datasets.
The challenge revolves around the inherent limitations of LLMs’ fixed context window sizes. Earlier methods for extending these windows, such as architectural modifications or fine-tuning, often incur substantial computational costs or degrade the model’s flexibility. Extensible Tokenization emerges as a solution, ingeniously converting standard token embeddings into a denser, information-rich format. This transformation allows LLMs to access a broader swath of information within the same context window size, thereby bypassing the constraints that have traditionally hampered their performance.
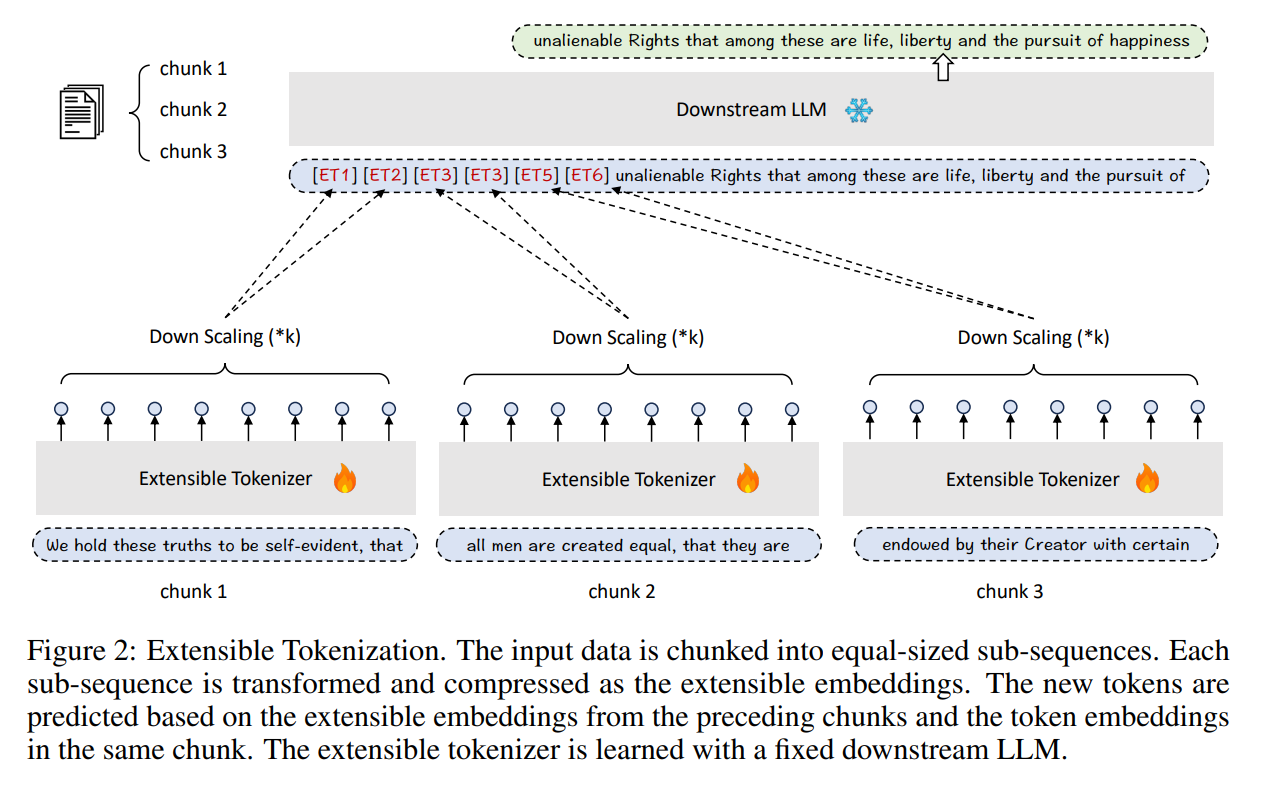
By serving as a middleware, it processes token embeddings into extensible embeddings, offering a more compact representation of the input context. This process preserves the original data’s integrity and enriches it, enabling LLMs to interpret significantly more information without increasing the context window’s size. What sets this approach apart is its flexibility; the scaling factor of Extensible Tokenization can be adjusted to accommodate different lengths of context, making it a versatile tool for various applications.
Comprehensive experiments have thoroughly evaluated the performance and results of Extensible Tokenization. These studies showcase the method’s superiority in enabling LLMs to process and understand extended contexts more efficiently and accurately. Notably, this approach does not require alterations to the LLMs’ core architecture or extensive retraining. This compatibility ensures that comprehensive contextual capabilities can be added to LLMs and their fine-tuned derivatives without compromising their existing functionalities.
Key highlights from the research include:
- Extensible tokenization significantly enhances LLMs’ context-processing capacity, enabling them to comprehend and utilize information from extended contexts efficiently.
- This methodology maintains the model’s original performance capabilities while adding new dimensions of contextual understanding.
- Through rigorous experimentation, the approach has been validated as effective, efficient, flexible, and compatible, demonstrating superior performance in long-context language modeling and understanding tasks.
In conclusion, Extensible Tokenization represents a pivotal advancement in artificial intelligence. Addressing a longstanding challenge in the enhancement of LLMs opens up new possibilities for developing AI systems capable of deep and comprehensive data analysis. This innovation enhances the capabilities of current models and sets the stage for future breakthroughs in artificial intelligence research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Extensible Tokenization: Revolutionizing Context Understanding in Large Language Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]