


Technological advancements have been pivotal in transcending the boundaries of what’s achievable in the domain of audio generation, especially in high-fidelity audio synthesis. As demand for more sophisticated and realistic audio experiences escalates, researchers have been propelled to innovate beyond conventional methods to resolve the persistent challenges within this field.
One primary issue that has hindered progress is the generation of high-quality music and singing voices, where existing models often grapple with spectral discontinuities and a need for more clarity in higher frequencies. These obstacles have impeded the production of crisp, lifelike audio, indicating a gap in the current technological capabilities.
Current advancements have largely focused on Generative Adversarial Networks (GANs) and neural vocoders, which have revolutionized audio synthesis through their ability to generate waveforms from acoustic properties efficiently. However, these models, including state-of-the-art vocoders like HiFiGAN and BigVGAN, have encountered limitations such as inadequate data diversity, limited model capacity, and challenges in scaling, particularly in the high-fidelity audio domain.

A research team has introduced the Enhanced Various Audio Generation via Scalable Generative Adversarial Networks (EVA-GAN). This model leverages an expansive dataset of 36,000 hours of high-fidelity audio and incorporates a novel Context Aware Module, pushing the envelope in spectral and high-frequency reconstruction. By expanding the model to approximately 200 million parameters, EVA-GAN marks a significant leap forward in audio synthesis technology.
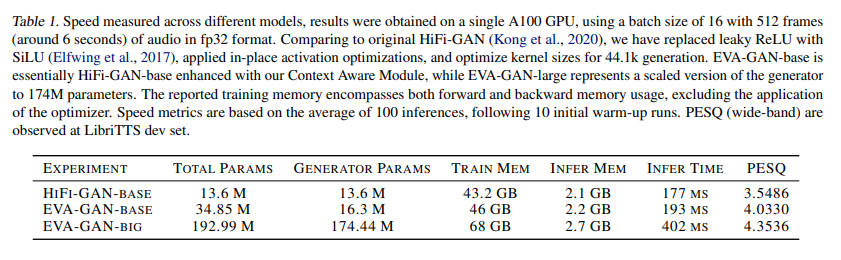
The core innovation of EVA-GAN lies in its Context Aware Module (CAM) and a Human-In-The-Loop artifact measurement toolkit designed to enhance model performance with minimal additional computational cost. CAM leverages residual connections and large convolution kernels to augment the context window and model capacity, addressing spectral discontinuity and blurriness in generated audio. This is complemented by the Human-In-The-Loop toolkit, which ensures the generated audio’s alignment with human perceptual standards, marking a significant step towards bridging the gap between artificial audio generation and natural sound perception.
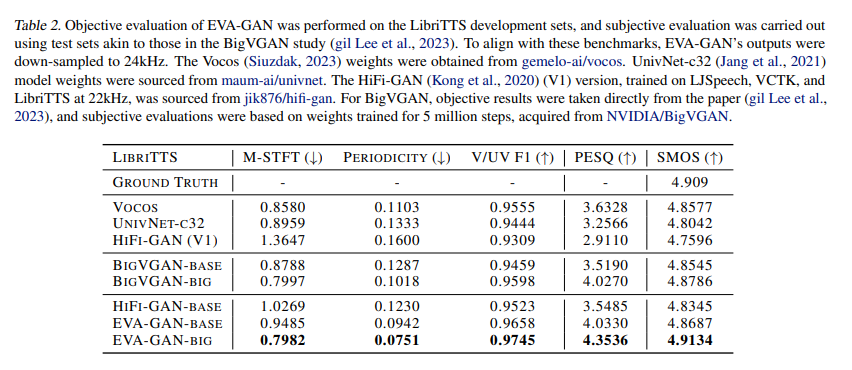
Performance evaluations of EVA-GAN have demonstrated its superior capabilities, particularly in generating high-fidelity audio. The model outperforms existing state-of-the-art solutions in robustness and quality, especially in out-of-domain data performance, setting a new benchmark in the field. For instance, EVA-GAN achieves a Perceptual Evaluation of Speech Quality (PESQ) score of 4.3536 and a Similarity Mean Option Score (SMOS) of 4.9134, significantly outperforming its predecessors and demonstrating its ability to replicate the richness and clarity of natural sound.
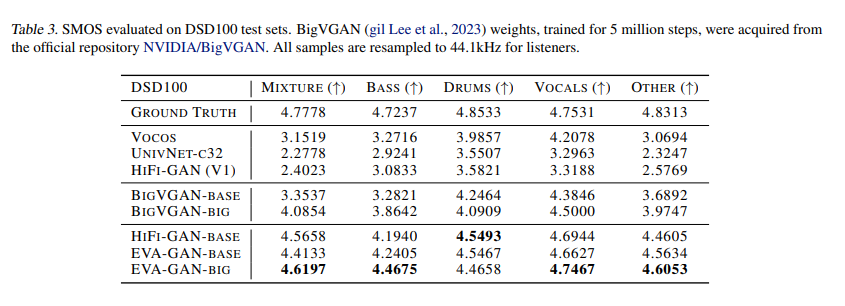
In conclusion, EVA-GAN represents a monumental stride in audio generation technology. By overcoming the longstanding challenges of spectral discontinuities and blurriness in high-frequency domains, it sets a new standard for high-quality audio synthesis. This innovation enriches the audio experience for end-users. It opens new avenues for research and development in speech synthesis, music generation, and beyond, heralding a new era of audio technology where the limits of realism are continuously expanded.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Enhanced Audio Generation through Scalable Technology appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #Sound #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]