


Pretrained on trillion-token corpora, large neural language models (LLMs) have achieved remarkable performance strides (Touvron et al., 2023a; Geng & Liu, 2023). However, the scalability benefits of such data for traditional n-gram language models (LMs) still need to be explored. This paper from the University of Washington and Allen Institute for Artificial Intelligence delves into the relevance of n-gram LMs in the era of neural LLMs and introduces groundbreaking advancements in their modernization.
The authors affirm the continued utility of n-gram LMs in text analysis and enhancing neural LLMs. To address this, they modernized traditional n-gram LMs by scaling training data to an unprecedented 1.4 trillion tokens, rivaling the size of major open-source text corpora (Together, 2023; Soldaini et al., 2023). This represents the largest n-gram LM to date. Departing from historical constraints on n (e.g., n ≤ 5), the authors highlight the advantages of larger n’s value. Figure 1 illustrates the enhanced predictive capacity of n-gram LMs with larger n values, challenging conventional limitations. Consequently, they introduce the concept of an ∞-gram LM, with unbounded n, utilizing a backoff variant (Jurafsky & Martin, 2000) for improved accuracy.
The ∞-gram LM leverages a suffix array, replacing impractical n-gram count tables. This implementation, referred to as the infini-gram engine, achieves remarkable efficiency with 7 bytes of storage per token. The suffix array, built on 1.4 trillion tokens using an 80-core CPU node in under three days, ensures low-latency, resource-efficient querying at less than 20 milliseconds for n-gram counting. The ∞-gram engine, a testament to innovation, makes on-disk indexes integral to inference.
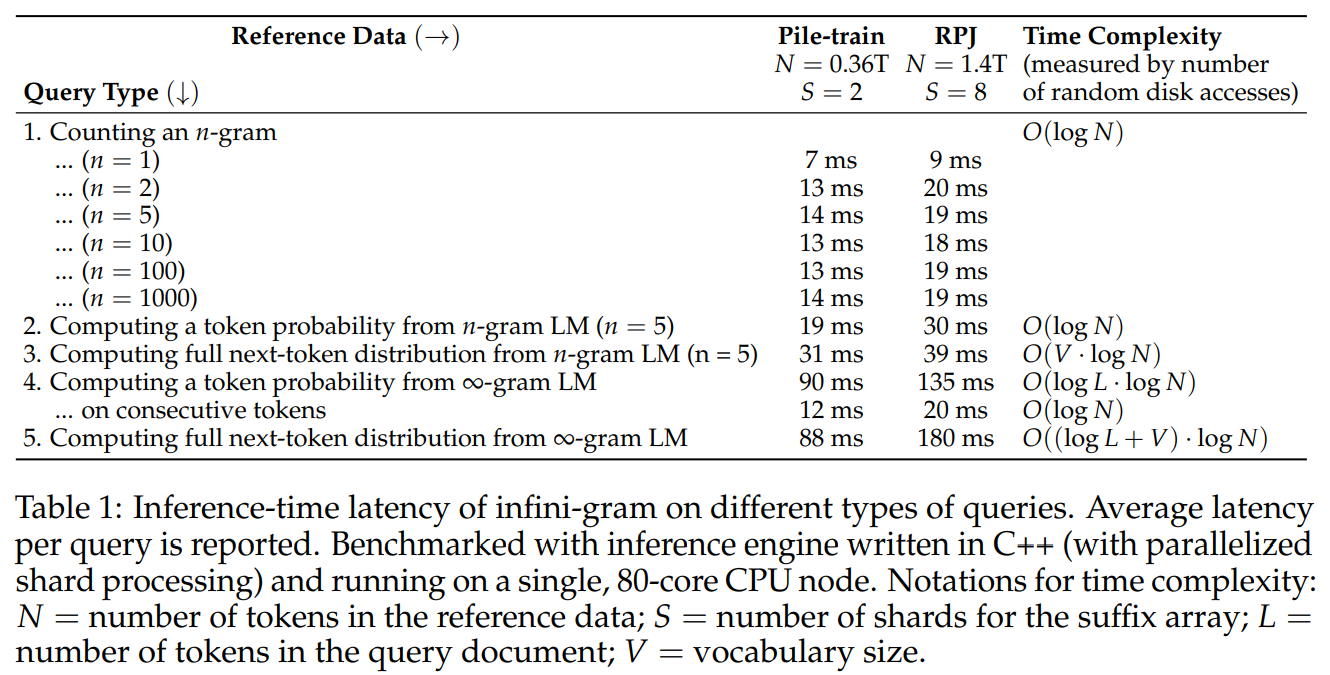
The ∞-gram LM, a conceptual extension of n-gram LMs, employs backoff judiciously to enhance predictive accuracy. Sparsity in ∞-gram estimates necessitate interpolation with neural LMs, addressing perplexity concerns. The paper introduces query types supported by Infini-gram, showcasing impressive latency benchmarks in Table 1.
Building on the suffix array implementation, the paper outlines efficient methods for n-gram counting, occurrence position retrieval, and document identification. Sharding strategies reduce latency proportional to the number of shards, optimizing processing times. Clever optimizations, such as reusing search results and on-disk search, further enhance the speed of ∞-gram computation.
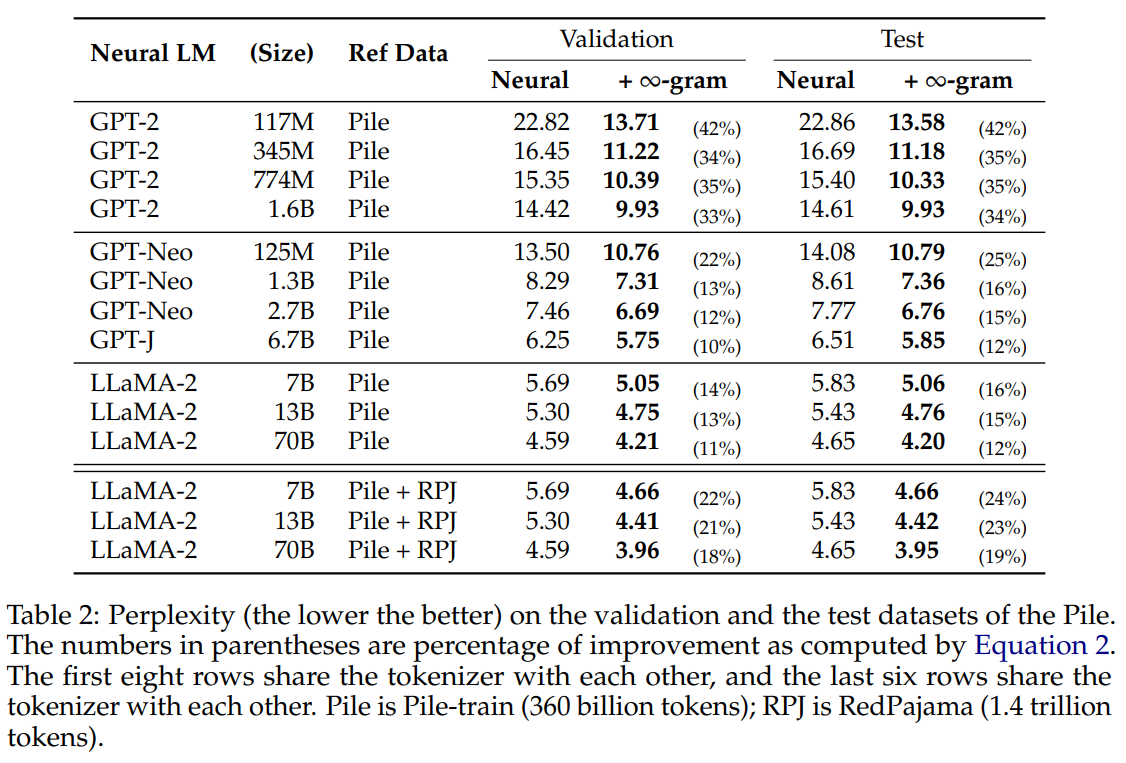
Infini-gram’s application across diverse neural LMs, including GPT-2, GPT-Neo, LLaMA-2, and SILO, demonstrates consistent perplexity improvements (Table 2). The paper underscores the significance of data diversity, revealing ∞-gram’s efficacy in complementing neural LMs across different model series.
Analyses with ∞-gram shed light on human-written and machine-generated text. Notably, ∞-gram exhibits high accuracy in predicting the next token based on human-written document prefixes. The paper establishes a positive correlation between neural LMs and ∞-gram, suggesting the latter’s potential to enhance LM performance in predicting human-written text.
The paper concludes with a visionary outlook, presenting preliminary applications of the Infini-gram engine. From understanding text corpora to mitigating copyright infringement, the possibilities are diverse. The authors anticipate further insightful analyses and innovative applications fueled by Infini-gram.
Check out the Paper and Model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post This AI Paper Proposes Infini-Gram: A Groundbreaking Approach to Scale and Enhance N-Gram Models Beyond Traditional Limits appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]