


Current multi-modal language models (LMs) face limitations in performing complex visual reasoning tasks. These tasks, such as compositional action recognition in videos, demand an intricate blend of low-level object motion and interaction analysis with high-level causal and compositional spatiotemporal reasoning. While these models excel in various areas, their effectiveness in tasks requiring detailed attention to fine-grained, low-level details alongside advanced rationale has yet to be fully explored or demonstrated, indicating a significant gap in their capabilities.
Current research in multi-modal LMs is advancing with auto-regressive models and adapters for visual processing. Key image-based models include Pix2seq, ViperGPT, VisProg, Chameleon, PaLM-E, LLaMA-Adapter, FROMAGe, InstructBLIP, Qwen-VL, and Kosmos-2, while video-based models like Video-ChatGPT, VideoChat, Valley, and Flamingo are gaining attention. Spatiotemporal video grounding is a new focus on object localization in media using linguistic cues. Attention-based models are pivotal in this research, utilizing techniques like multi-hop feature modulation and cascaded networks for enhanced visual reasoning.
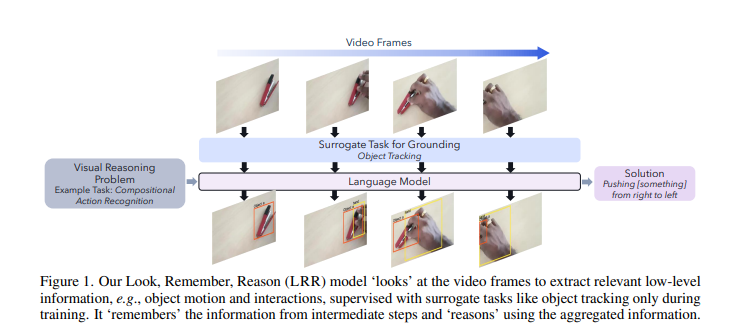
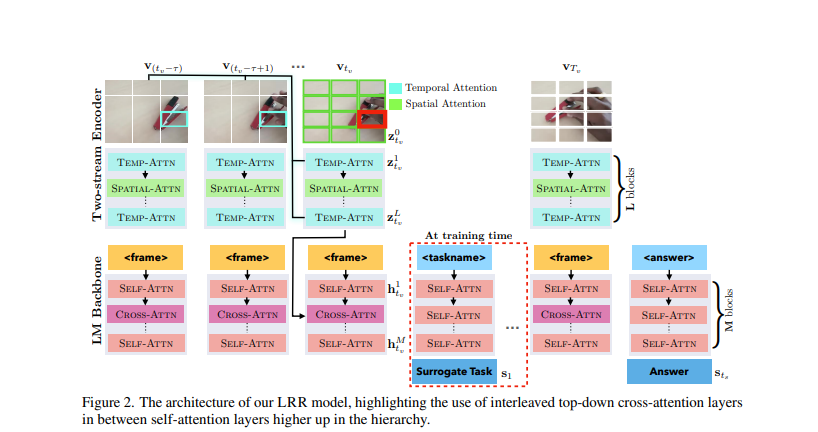
Researchers at Qualcomm AI Research have introduced a multi-modal LM, trained end-to-end on tasks like object detection and tracking, to improve low-level visual skills. It employs a two-stream video encoder with spatiotemporal attention for static and motion cues, following a “Look, Remember, Reason” process.
The research focuses on enhancing a multi-model LM and uses ACRE, CATER, and STAR datasets. The surrogate tasks of object recognition, re-identification, and identifying the state of the blicket machine are introduced during training with a probability of 30 after each context trial or query. Using fewer parameters, the model is trained with the OPT-125M and OPT-1.3B architectures. The model is trained until convergence with a batch size of 4 using the AdamW optimizer.
The LRR framework leads the STAR challenge leaderboard as of January 2024, showcasing its superior performance in video reasoning. The model’s effectiveness is proven across various datasets like ACRE, CATER, and Something-Else, indicating its adaptability and proficiency in processing low-level visual cues. The LRR model’s end-to-end trainability and performance surpassing task-specific methods underscore its capability to enhance video reasoning.
In conclusion, the framework follows a three-step “Look, Remember, Reason” process where visual information is extracted using low-level graphic skills and integrated to arrive at a final answer. The LRR model effectively captures static and motion-based cues in videos through a two-stream video encoder with spatiotemporal attention. Future work could involve exploring the inclusion of datasets like ACRE by treating images as still videos, further improving the LRR model’s performance. The LRR framework can be extended to other visual reasoning tasks and datasets, potentially enhancing its applicability and performance in a broader range of scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Enhancing Low-Level Visual Skills in Language Models: Qualcomm AI Research Proposes the Look, Remember, and Reason (LRR) Multi-Modal Language Model appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MultimodalAI #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]