


In audio processing, speaker diarization is a critical yet challenging task. This technique, pivotal in discerning individual voices in multi-speaker environments, holds immense value across various applications. From enhancing the clarity of conference calls to aiding in transcribing legal proceedings, its utility is far-reaching. Despite its importance, the task is fraught with complexities. Traditional diarization methods, although advanced, often grapple with issues like overlapping speech and varying voice modulations, leading to inaccuracies in identifying ‘who spoke when.’
To tackle these challenges, the research community has employed a range of methodologies. The backbone of most diarization systems is a combination of voice activity detection, speaker turn detection, and clustering algorithms. These systems typically fall into two categories: modular and end-to-end systems. Modular systems consist of separately trained components, each handling a specific aspect of diarization. Conversely, end-to-end systems aim to optimize the entire diarization process using complex loss functions. However, both approaches are limited, particularly in scenarios involving overlapping speech or diverse speaking styles.
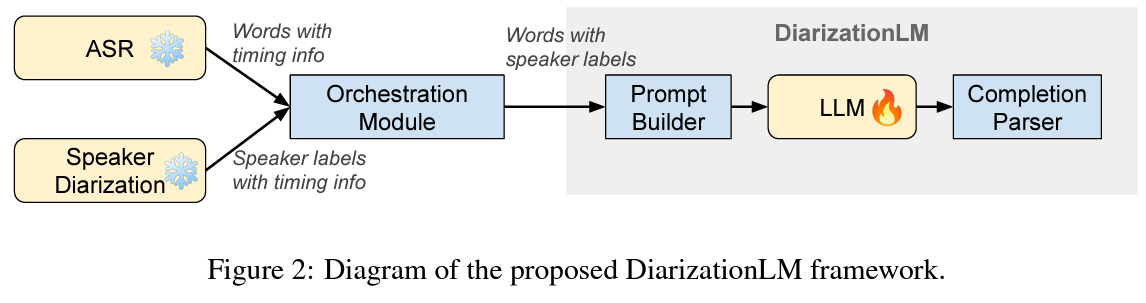
Enter ‘DiarizationLM,’ a groundbreaking framework developed by researchers at Google that promises to revolutionize speaker diarization by harnessing the power of large language models (LLMs). This innovative approach takes the outputs from automatic speech recognition (ASR) and speaker diarization systems and refines them using LLMs. It involves a post-processing step that enhances speaker attribution accuracy by interpreting the speech’s semantic and contextual nuances. The framework represents a shift from solely relying on acoustic signals to incorporating the rich information embedded in speech content.
The inner workings of DiarizationLM are as intriguing as its premise. It begins by translating the outputs of ASR and speaker diarization systems into a compact textual format. This format serves as a prompt for the LLMs to refine the diarization results. By analyzing the textual content, the LLMs can more accurately attribute speech segments to the correct speakers, thus reducing diarization errors. The framework employs a fine-tuning model, such as PaLM 2-S, to target and rectify these diarization inaccuracies.
The performance of DiarizationLM is nothing short of impressive. Its efficacy is demonstrated through significant reductions in word diarization error rates. When tested on the Fisher and Callhome datasets, the framework achieved relative decreases of 25.9% and 31% in word diarization error rate, respectively. These figures are a testament to the framework’s capability to enhance the precision of speaker diarization systems. What’s more, these improvements were observed across different speech domains, showcasing the versatility of DiarizationLM.
DiarizationLM stands as a testament to the evolving landscape of speaker diarization. It addresses the longstanding challenges of accurate speaker attribution by integrating the analytical prowess of large language models into the post-processing of diarization outputs. This advancement marks a significant leap in the technical capabilities of speech processing systems and paves the way for more nuanced and accurate interpretations of multi-speaker audio. With its demonstrated ability to significantly reduce diarization errors, DiarizationLM is poised to redefine the standards of speaker diarization, making it an invaluable tool in any scenario where deciphering individual voices is key.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
The post Google AI Researchers Introduce DiarizationLM: A Machine Learning Framework to Leverage Large Language Models (LLM) to Post-Process the Outputs from a Speaker Diarization System appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]