


Parallel Text-to-Speech (TTS) models are commonly used for on-the-fly speech synthesis, providing enhanced control and faster synthesis than traditional auto-regressive models. Despite their advantages, parallel models, particularly those based on transformer architecture, face challenges regarding incremental synthesis. This limitation arises from their fully parallel structure. The growing prevalence of real-time and streaming applications has spurred a need for TTS systems that can generate speech incrementally, catering to the demand for streaming TTS. This adaptation is crucial for achieving lower response latency and enhancing the user experience.
Researchers from NVIDIA Corporation propose Incremental FastPitch, a variant of FastPitch, which can incrementally produce high-quality Mel chunks with lower latency for real-time speech synthesis. The proposed model improves the architecture with chunk-based FFT blocks, training with receptive field-constrained chunk attention masks, and inference with fixed-size past model states. This results in comparable speech quality to parallel FastPitch but significantly lower latency. It employs training with constrained receptive fields and explores the use of both static and dynamic chunk masks. This exploration is crucial to ensure the model effectively aligns with limited receptive field inference during synthesis.
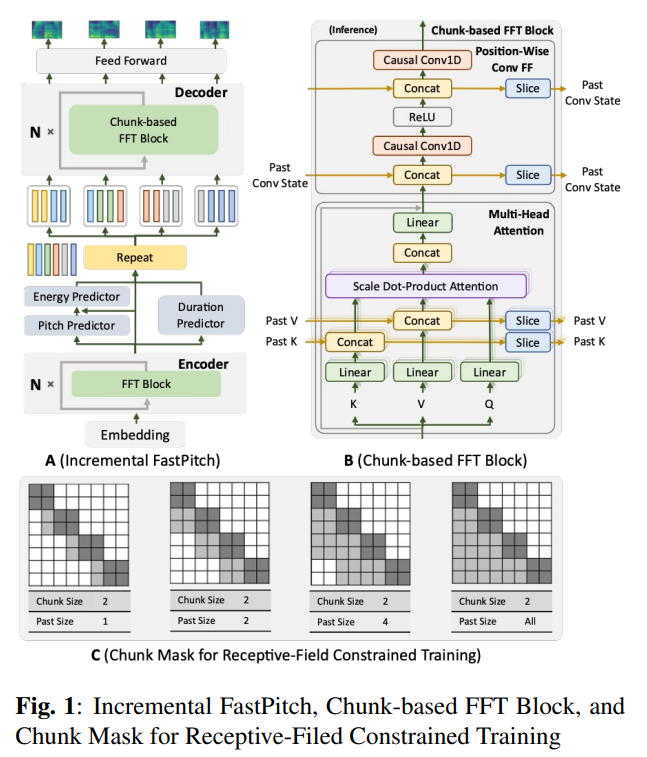
A Neural TTS system typically comprises two main components: an acoustic model and a vocoder. The process begins with converting text into Mel-spectrograms using acoustic models like Tacotron 2, FastSpeech, FastPitch, and GlowTTS. Subsequently, the Mel features are transformed into waveforms using vocoders such as WaveNet, WaveRNN, WaveGlow, and HiF-GAN. The study also mentions using the Chinese Standard Mandarin Speech Corpus for training and evaluation, which contains 10,000 audio clips of a single Mandarin female speaker. The proposed model parameters follow the open-source FastPitch implementation, with modifications in the decoder using causal convolution in the position-wise feed-forward layers.
The Incremental FastPitch is a variant of FastPitch that incorporates chunk-based FFT blocks in the decoder to enable incremental synthesis of high-quality Mel chunks. The model is trained using receptive field-constrained chunk attention masks, which help the decoder adjust to the limited receptive field in incremental inference. The proposed model also utilizes fixed-size past model states during inference to maintain Mel continuity across chunks. The Chinese Standard Mandarin Speech Corpus trains and evaluates the model. The model parameters follow the open-source FastPitch implementation, using causal convolution in the position-wise feed-forward layers. The Mel-spectrogram is generated through an FFT size of 1024, a hop length of 256, and a window length of 1024, applied to the normalized waveform.

Experimental results show that Incremental FastPitch can produce speech quality comparable to parallel FastPitch, with significantly lower latency, making it suitable for real-time speech applications. The proposed model incorporates chunk-based FFT blocks, training with receptive field-constrained chunk attention masks, and inference with fixed-size past model states, contributing to improved performance. A visualized ablation study demonstrates that incremental FastPitch can generate Mel-spectrograms with almost no observable difference compared to parallel FastPitch, highlighting the effectiveness of the proposed model.
In conclusion, The Incremental FastPitch, a variant of FastPitch, enables incremental synthesis of high-quality Mel chunks with low latency for real-time speech applications. The proposed model incorporates chunk-based FFT blocks, training with receptive field constrained chunk attention masks, and inference with fixed size past model states, resulting in speech quality comparable to parallel FastPitch but with significantly lower latency. A visualized ablation study shows that Incremental FastPitch can generate Mel-spectrograms with almost no observable difference compared to parallel FastPitch, highlighting the effectiveness of the proposed model. The model parameters follow the open-source FastPitch implementation, with modifications in the decoder using causal convolution in the position-wise feed-forward layers. Incremental FastPitch offers a faster and more controllable speech synthesis process, making it a promising approach for real-time applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
The post This AI Paper from NVIDIA Unveils ‘Incremental FastPitch’: Revolutionizing Real-Time Speech Synthesis with Lower Latency and High Quality appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Sound #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]