

Researchers from ETH Zurich explore simplifications in the design of deep Transformers, aiming to make them more robust and efficient. Modifications are proposed by combining signal propagation theory and empirical observations, enabling the removal of various components from standard transformer blocks without compromising training speed or performance.
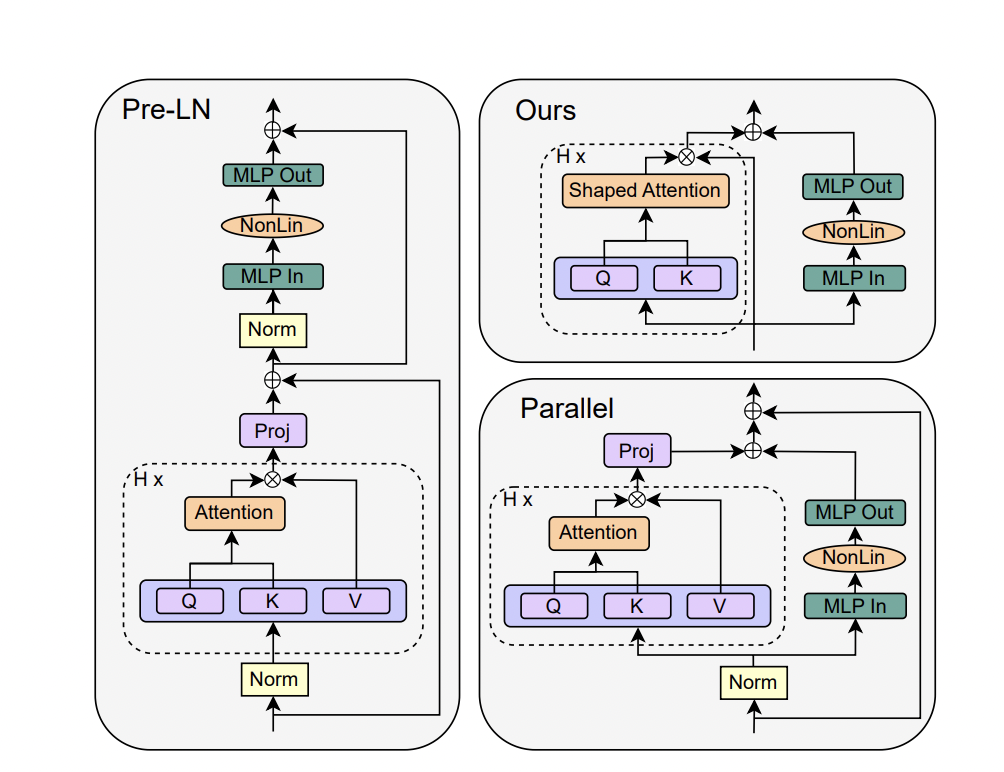
The research presents a study on simplifying transformer blocks in deep neural networks, specifically focusing on the standard transformer block. Drawing inspiration from signal propagation theory, it explores the arrangement of identical building blocks, incorporating attention and MLP sub-blocks with skip connections and normalization layers. It also introduces the parallel block, which computes the MLP and attention sub-blocks in parallel for improved efficiency.
The study examines the simplification of transformer blocks in deep neural networks, focusing specifically on the standard transformer block. It investigates the necessity of various components within the block and explores the possibility of removing them without compromising training speed. The motivation for simplification arises from the complexity of modern neural network architectures and the gap between theory and practice in deep learning.
The approach combines signal propagation theory and empirical observations to propose modifications for simplifying transformer blocks. The study conducted experiments on autoregressive decoder-only and BERT encoder-only models to assess the performance of the simplified transformers. It performs additional experiments and ablations to study the impact of removing skip connections in the attention sub-block and the resulting signal degeneracy.
The research proposed modifications to simplify transformer blocks by removing skip connections, projection/value parameters, sequential sub-blocks, and normalization layers. These modifications maintain standard transformers’ training speed and performance while achieving faster training throughput and utilizing fewer parameters. The study also investigated the impact of different initialization methods on the performance of simplified transformers.
The proposed simplified transformers achieve comparable performance to standard transformers while using 15% fewer parameters and experiencing a 15% increase in training throughput. The study presents simplified deep-learning architectures that can reduce the cost of large transformer models. The experimental results support the effectiveness of the simplifications across various settings and emphasize the significance of proper initialization for optimal results.
The recommended future research is to investigate the effectiveness of the proposed simplifications on larger transformer models, as the study primarily focused on relatively small models compared to the largest transformers. It also suggests conducting a comprehensive hyperparameter search to enhance the performance of the simplified blocks, as the study only tuned key hyperparameters and relied on default choices. It proposes exploring hardware-specific implementations of the simplified blocks to achieve additional improvements in training speed and performance potentially.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
The post Can Transformer Blocks Be Simplified Without Compromising Efficiency? This AI Paper from ETH Zurich Explores the Balance Between Design Complexity and Performance appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]