


Transformer-based LLMs have significantly advanced machine learning capabilities, showcasing remarkable proficiency in domains like natural language processing, computer vision, and reinforcement learning. These models, known for their substantial size and computational demands, have been at the forefront of AI development. However, a central challenge still needs to be solved in optimizing their performance without further escalating their already considerable size and computational requirements.
In the realm of LLMs, the concept of over-parameterization is prevalent. It implies that these models possess more parameters than necessary for effective learning and functioning, leading to inefficiencies. Addressing this inefficiency without compromising the models’ learned capabilities is a key issue. Traditional methods involve pruning, which is the process of removing parameters from a model to enhance efficiency. However, this often leads to a trade-off between model size and effectiveness, as indiscriminate pruning can degrade performance.
Researchers from MIT and Microsoft introduce LAyer-SElective Rank reduction (LASER) approach that revolutionizes the optimization of LLMs by selectively targeting higher-order components of weight matrices for reduction. Unlike traditional methods, which uniformly trim parameters across the model, LASER focuses on specific layers within the Transformer model, particularly targeting the Multi-Layer Perceptron (MLP) and attention layers. This more nuanced approach allows for preserving essential components while eliminating redundancies.
The methodology behind LASER is grounded in the principles of singular value decomposition. This mathematical technique identifies and subsequently reduces the higher-order components in weight matrices. By concentrating on particular matrices within the MLP and attention layers, LASER ensures that only the most relevant and necessary components are retained. This targeted reduction allows for more sophisticated model refinement, maintaining its core capabilities while enhancing its overall efficiency.
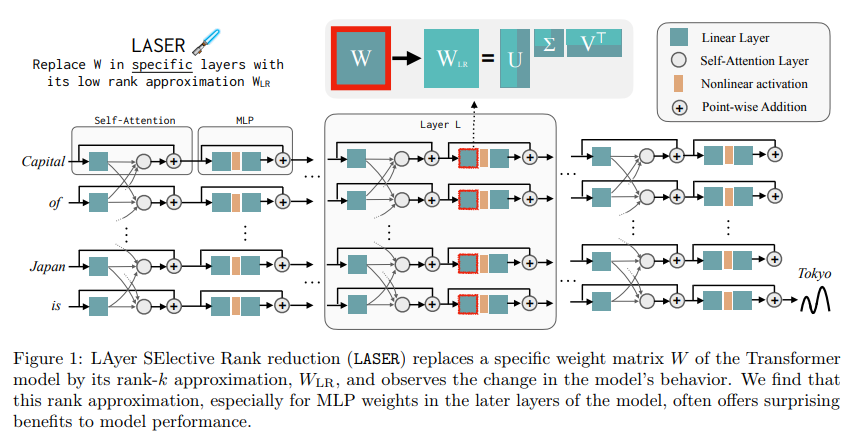
Regarding the impact of LASER, the results are nothing short of remarkable. The method has shown significant gains in accuracy across various reasoning benchmarks in NLP. These advancements were achieved without additional training or parameters, a notable feat given the complexity of these models. One of the most striking outcomes of LASER is its effectiveness in handling information that is less frequently represented in the training data. It indicates an increase in the models’ accuracy and a boost in their robustness and factuality. The method allows LLMs to handle nuanced and less common data better, thus broadening their applicability and effectiveness.
In conclusion, LASER stands as a significant advancement in optimizing LLMs. The efficiency of models can be improved by selectively reducing components in weight matrices without adding computational burdens. This technique not only elevates the performance of LLMs in familiar tasks but also expands their capabilities in processing and understanding less frequent, nuanced data. LASER marks a notable step forward in AI, paving the way for more refined and efficient language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
What if I told you that you can simultaneously enhance an LLM's task performance and reduce its size with no additional training?
We find selective low-rank reduction of matrices in a transformer can improve its performance on language understanding tasks, at times by 30% pts!
pic.twitter.com/4i9aZPpwlJ
— Pratyusha Sharma (@pratyusha_PS) December 24, 2023
The post This Paper from MIT and Microsoft Introduces ‘LASER’: A Novel Machine Learning Approach that can Simultaneously Enhance an LLM’s Task Performance and Reduce its Size with no Additional Training appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]