


The exploration of natural language processing has been revolutionized with the advent of LLMs like GPT. These models showcase exceptional language comprehension and generation abilities but encounter significant hurdles. Their static knowledge base often challenges them, leading to outdated information and response inaccuracies, especially in scenarios demanding domain-specific insights. This gap calls for innovative strategies to bridge the limitations of LLMs, ensuring their practical applicability and reliability in diverse, knowledge-intensive tasks.
The traditional approach has fine-tuned LLMs with domain-specific data to address these challenges. While this method can yield substantial improvements, it has drawbacks. It necessitates a high resource investment and specialized expertise, limiting its adaptability to the constantly evolving information landscape. This approach cannot dynamically update the model’s knowledge base, which is essential for handling rapidly changing or highly specialized content. These limitations point towards the need for a more flexible and dynamic method to augment LLMs.
Researchers from Tongji University, Fudan University, and Tongji University have presented a survey on Retrieval-Augmented Generation (RAG), an innovative methodology developed by researchers to enhance the capabilities of LLMs. This approach ingeniously merges the model’s parameterized knowledge with dynamically accessible, non-parameterized external data sources. RAG first identifies and extracts relevant information from external databases in response to a query. The retrieved data forms the foundation upon which the LLM generates its responses. This process enriches the model’s reactions with current and domain-specific information and significantly diminishes the occurrence of hallucinations, a common issue in LLM responses.

Delving deeper into RAG’s methodology, the process begins with a sophisticated retrieval system that scans through extensive external databases to locate information pertinent to the query. This system is finely tuned to ensure the relevance and accuracy of the information being sourced. Once the relevant data is identified, it’s seamlessly integrated into the LLM’s response generation process. The LLM, now equipped with this freshly sourced information, is better positioned to produce responses that are not only accurate but also up-to-date, addressing the inherent limitations of purely parameterized models.
The performance of RAG-augmented LLMs has been remarkable. A significant reduction in model hallucinations has been observed, directly enhancing the reliability of the responses. Users can now receive answers that are not only rooted in the model’s extensive training data but also supplemented with the most current information from external sources. This aspect of RAG, where the sources of the retrieved information can be cited, adds a layer of transparency and trustworthiness to the model’s outputs. RAG’s ability to dynamically incorporate domain-specific knowledge makes these models versatile and adaptable to various applications.
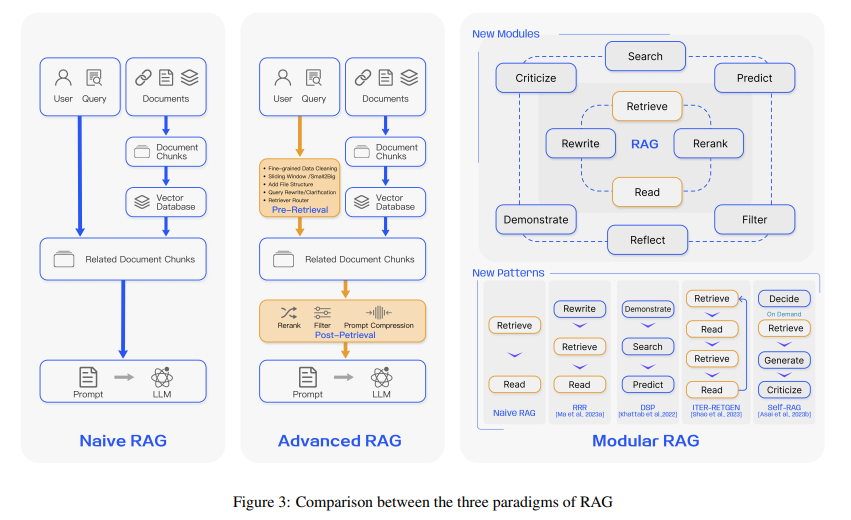
In a nutshell:
- RAG represents a groundbreaking approach in natural language processing, addressing critical challenges LLMs face.
- By bridging parameterized knowledge with external, non-parameterized data, RAG significantly enhances the accuracy and relevance of LLM responses.
- The method’s dynamic nature allows for incorporating up-to-date and domain-specific information, making it highly adaptable.
- RAG’s performance is marked by a notable reduction in hallucinations and increased response reliability, bolstering user trust.
- The transparency afforded by RAG, through source citations, further establishes its utility and credibility in practical applications.
This exploration into RAG’s role in augmenting LLMs underlines its significance and potential in shaping the future of natural language processing, opening new avenues for research and development in this dynamic and ever-evolving field.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post This AI Paper Outlines the Three Development Paradigms of RAG in the Era of LLMs: Naive RAG, Advanced RAG, and Modular RAG appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]