


Open-source Large Language Models (LLMs) such as LLaMA, Falcon, and Mistral offer a range of choices for AI professionals and scholars. Yet, the majority of these LLMs have only made available select components like the end-model weights or inference scripts, with technical documents often narrowing their focus to broader design aspects and basic metrics. This approach restricts advances in the field by reducing clarity in the training methodologies of LLMs, leading to repeated efforts by teams to uncover numerous aspects of the training procedure.
A team of researchers from Petuum, MBZUAI, USC, CMU, UIUC, and UCSD introduced LLM360 to support open and collaborative AI research by making the end-to-end LLM training process transparent and reproducible by everyone. LLM360 is an initiative to fully open-source LLMs that advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community.
The closest project to LLM360 is Pythia, which also aims to achieve the full reproducibility of LLMs. EleutherAI models such as GPT-J and GPT-NeoX have been released with training code, datasets, and intermediate model checkpoints, demonstrating the value of open-source training code. INCITE, MPT, and OpenLLaMA were released with training code and training datasets, with RedPajama also releasing intermediate model checkpoints.
LLM360 releases two 7B parameter LLMs, AMBER and CRYSTALCODER, along with their training code, data, intermediate checkpoints, and analyses. The details of the pre-training dataset, including data preprocessing, format, data mixing ratios, and architectural details of the LLM model, are reviewed in the study.
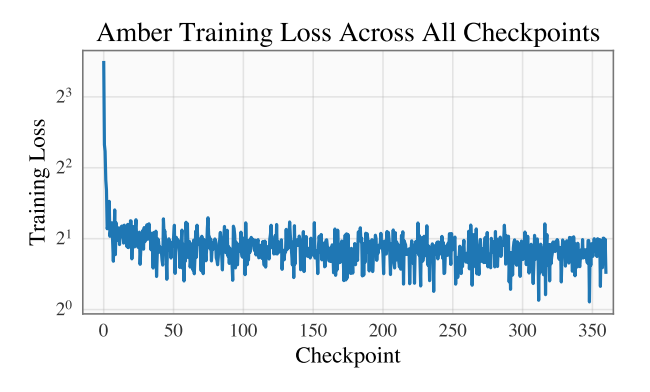
The research mentions using the memorization score introduced in previous work and releasing metrics, data chunks, and checkpoints for researchers to find their correspondence easily. The study also emphasizes the importance of removing the data LLMs are pre trained on, along with details about data filtering, processing, and training order, to assess the risks of LLMs.
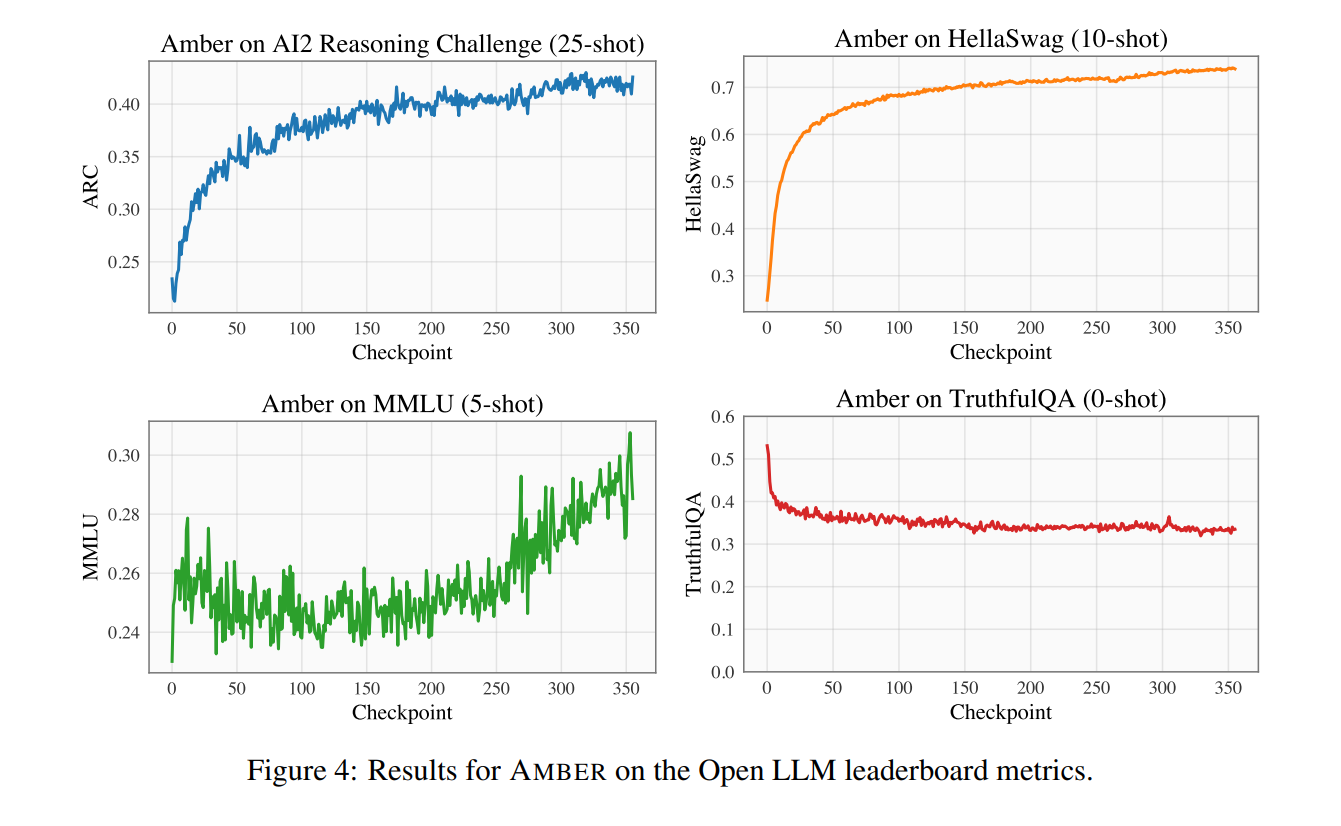
The research presents benchmark results on four datasets, namely ARC, HellaSwag, MMLU, and TruthfulQA, showing the model’s performance during pre-training. The evaluation scores of HellaSwag and ARC monotonically increase during pre-training, while the TruthfulQA score decreases. The MMLU score initially decreases and then starts to grow. AMBER’s performance is relatively competitive in scores such as MMLU, but it lags beyond in ARC. Finetuned AMBER models show strong performance compared to other similar models.
In conclusion, LLM360 is an initiative for comprehensive and fully open-sourced LLMs to advance transparency within the open-source LLM pre-training community. The study released two 7B LLMs, AMBER and CRYSTALCODER, along with their training code, data, intermediate model checkpoints, and analyses. The study emphasizes the importance of open sourcing. LLMs from all angles, including releasing checkpoints, data chunks, and evaluation results, to enable comprehensive analysis and reproducibility.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
1/7 We are thrilled to launch LLM360 — pushing the frontier of open-source & transparent LLMs!
Starting with Amber (7B) & CrystalCoder (7B), we are releasing brand new pre-trained LLMs with all training code, data, and up to 360 model checkpoints.
https://t.co/ZcLPtYQhdQ pic.twitter.com/qpHU2DhwWF
— LLM360 (@llm360) December 11, 2023
The post Meet LLM360: The First Fully Open-Source and Transparent Large Language Models (LLMs) appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]