


The problem of a mediator learning to coordinate a group of strategic agents is considered through action recommendations without knowing their underlying utility functions, such as routing drivers through a road network. The challenge lies in the difficulty of manually specifying the quality of these recommendations, making it necessary to provide the mediator with data on desired coordination behavior. This transforms the problem into one of multi-agent imitation learning (MAIL). A fundamental question in MAIL is identifying the right objective for the learner, explored through the development of personalized route recommendations for users.
Current research to solve the challenges in multi-agent imitation learning includes several methodologies. Single-agent imitation Learning techniques like behavioral cloning reduce imitation to supervised learning but suffer from covariate shifts, leading to compounding errors. Interactive approaches like inverse reinforcement learning (RL) allow learners to observe the consequences of their actions, preventing compounding errors but are sample-inefficient. The next approach is multi-agent imitation learning in which the concept of the regret gap has been explored but not utilized fully in Markov Games. The third approach, Inverse game theory focuses on recovering utility functions rather than learning coordination from demonstrations.
Researchers from Carnegie Mellon University have proposed an alternative objective for multi-agent imitation learning (MAIL) in Markov Games called the regret gap, which explicitly accounts for potential deviations by agents in the group. They investigated the relationship between the value and regret gaps, showing that while the value gap can be minimized using single-agent imitation learning (IL) algorithms, it does not prevent the regret gap from becoming arbitrarily large. This finding indicates that achieving regret equivalence is more challenging than achieving value equivalence in MAIL. To address this, two efficient reductions are developed to no-regret online convex optimization, (a) MALICE, under a coverage assumption on the expert, and (b) BLADES, with access to a queryable expert.
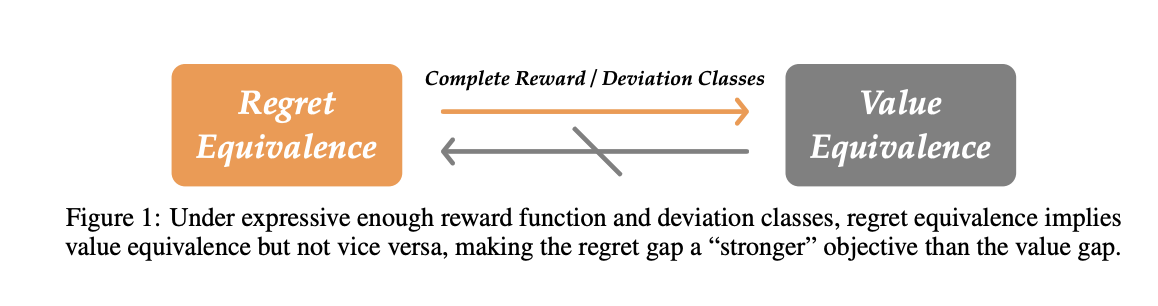
Although the value gap is considered a ‘weaker’ objective, it can be a reasonable learning objective in real-world applications where agents are non-strategic. The natural multi-agent generalization of single-agent imitation learning algorithms can efficiently minimize the value gap, making it relatively easy to achieve in MAIL. Two such single-agent IL algorithms, Behavior Cloning (BC) and Inverse Reinforcement Learning (IRL), are used to minimize the value gap. These algorithms run over joint policies where BC and IRL are applied to the multi-agent setting, becoming Joint Behavior Cloning (J-BC) and Joint Inverse Reinforcement Learning (J-IRL). These adaptations result in the same value gap bounds as in the single-agent setting.
Multi-agent Aggregation of Losses to Imitate Cached Experts (MALICE), is an efficient algorithm extending the ALICE algorithm to the multi-agent setting. ALICE is an interactive algorithm that uses importance sampling to re-weight the BC loss based on the density ratio between the current learner policy and that of the expert. It requires full demonstration coverage to ensure finite importance weights. ALICE utilizes a no-regret algorithm to learn a policy that minimizes reweighed on-policy error, ensuring a linear-in-H bound on the value gap under a recoverability assumption. MALICE adapts these principles to multi-agent environments, providing a robust solution for minimizing the regret gap.
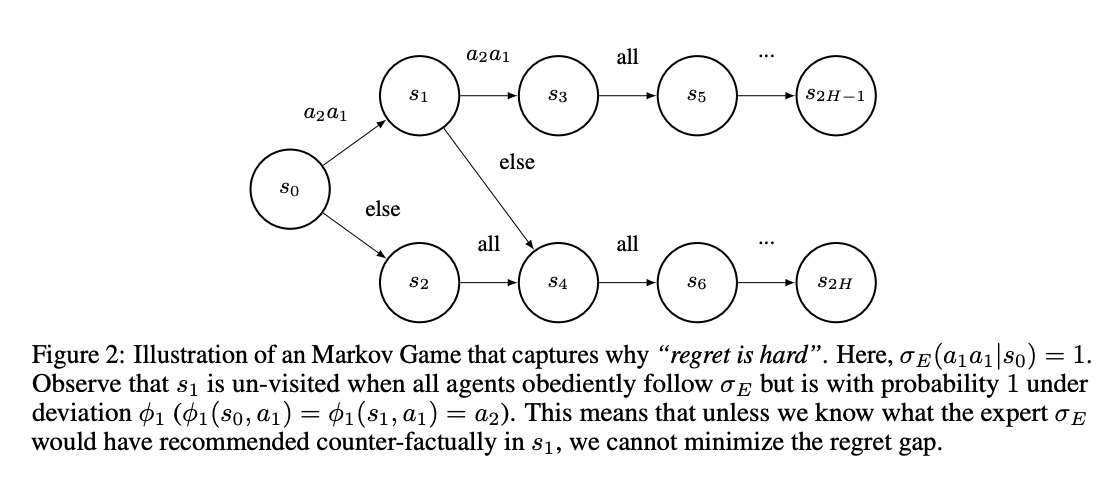
In conclusion, researchers from Carnegie Mellon University have introduced an alternative objective for MAIL in Markov Games called the regret gap. For strategic agents that are not mere puppets, another source of distribution shift arises from deviations by agents within the population. This shift cannot be efficiently controlled through environmental interaction, such as inverse RL. So, it requires estimating the expert’s actions in counterfactual states. Utilizing this insight, the researchers derived two reductions that can minimize the regret gap under a coverage or queryable expert assumption. Future work includes developing and implementing practical approximations of these idealized algorithms.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post CMU Researchers Explore Expert Guidance and Strategic Deviations in Multi-Agent Imitation Learning appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]