


As the adage “an image is worth a thousand words” suggests, adding images as a second modality to 3D production gives substantial advantages over systems that only use text. Images primarily provide detailed, rich visual information that language may only partially or not describe. An image, for example, may clearly and immediately express minor characteristics like textures, colors, and spatial connections, but a word description may need help to fully represent the same level of detail or use very long explanations. Because the system can directly reference actual visual cues instead of interpreting written descriptions, which can vary widely in complexity and subjectivity, this visual specificity helps generate more accurate and detailed 3D models.
Additionally, users may explain their intended outcomes more simply and directly when they utilize visuals, especially for individuals who find it difficult to express their visions in words. This multimodal method may serve a broader range of creative and practical applications, which combines the contextual depth of text with the richness of visual data to provide a more reliable, user-friendly, and effective 3D production process. While useful, using photos as an alternative modality for 3D object development also presents several difficulties. In contrast to text, images have many additional elements, such as color, texture, and spatial connections, making them more difficult to analyze and understand correctly using a single encoder like CLIP.
Furthermore, a considerable variation in light, form, or self-occlusion of the object might result in a view synthesis that could be more precise and consistent, which can provide incomplete or hazy 3D models. Advanced, computationally demanding techniques are required to effectively decode visual information and guarantee consistent appearance across many views due to the complexity of image processing. Researchers have transformed 2D item images into 3D models using various diffusion model methodologies, such as Zero123 and other recent efforts. One drawback of image-only systems is that, while the synthetic views seem great, the reconstructed models sometimes need more geometric correctness and intricate texturing, especially regarding the object’s rear perspectives. The main cause of this problem is large geometric discrepancies between the produced or synthesized perspectives.
As a result, non-matching pixels are averaged in the final 3D model during reconstruction, resulting in blurry textures and rounded geometry. In essence, image-conditioned 3D generation is an optimization problem with more restrictive restrictions compared to text-conditioned generation. Because a limited quantity of 3D data is available, optimizing 3D models with precise features becomes more difficult because the optimization process tends to stray from the training distributions. For instance, if the training dataset contains a range of horse styles, creating a horse just from text descriptions may result in detailed models. However, the novel-view texture creation may readily diverge from the taught distributions when an image specifies specific fur features, shapes, and textures.
To tackle these issues, the research team from ByteDance provides ImageDream in this work. The research team proposes a multilevel image-prompt controller that can be easily incorporated into the current architecture while considering canonical camera coordination across various object instances. In particular, according to canonical camera coordination, the produced picture must depict the object’s centered front view while using the default camera settings (identity rotation and zero translation). This makes the process of translating differences in the input picture to three dimensions simpler. By providing hierarchical control, the multilevel controller streamlines the information transfer process by directing the diffusion model from the picture input to every architectural block.
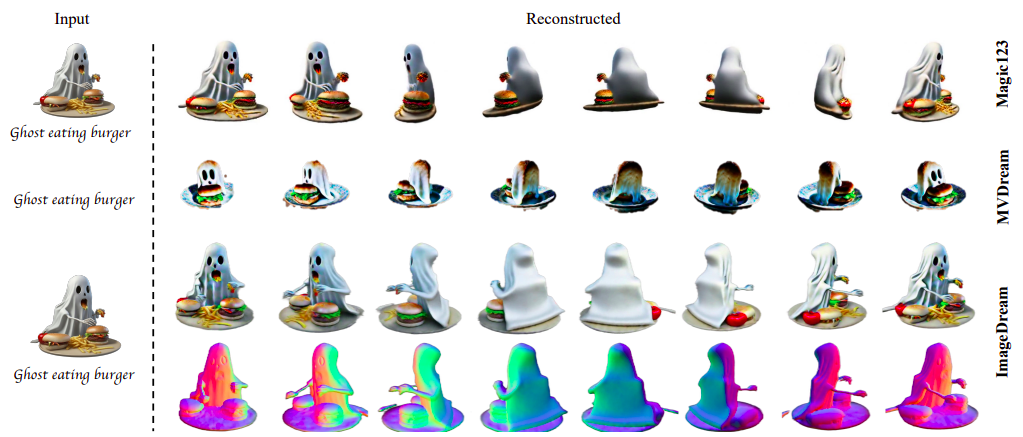
Compared to strictly text-conditioned models like MVDream, ImageDream excels in producing objects with the right geometry from a given image, as seen in Fig. 1. This allows users to use well-developed image generation models for improved image-text alignment. Regarding geometry and texture quality, ImageDream outperforms current state-of-the-art (SoTA) zero-shot single-image 3D model generators like Magic123. ImageDream outperforms previous SoTA techniques, as shown by their thorough evaluation in the experimental part, which includes quantitative assessments and qualitative comparisons through user tests.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post ByteDance Researchers Introduce ‘ImageDream’: An Innovative Image-Prompt and Multi-View Diffusion Model for 3D Object Generation appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]