


TensorOpera has announced the launch of its groundbreaking small language model, Fox-1, through an official press release. This innovative model represents a significant step forward in small language models (SLMs), setting new benchmarks for scalability and performance in generative AI, particularly for cloud and edge computing applications.
Fox-1-1.6B boasts a 1.6 billion parameter architecture, distinguishing it from other SLMs due to its superior performance and efficiency. The model has been meticulously designed to cater to the needs of developers and enterprises aiming for scalable and efficient AI deployment. It surpasses similar models from industry giants such as Apple, Google, and Alibaba.
A key feature of Fox-1 is its integration into TensorOpera’s AI and FedML platforms. This integration facilitates the deployment, training, and creation of AI applications across various platforms and devices, ranging from high-powered GPUs in the cloud to edge devices like smartphones and AI-enabled PCs. This versatility underscores TensorOpera’s commitment to providing a scalable, generative AI platform that enhances ownership and efficiency across diverse computing environments.
SLMs, including Fox-1, offer several advantages over larger language models (LLMs). They are designed to operate with significantly reduced latency and require less computational power, making them ideal for environments with limited resources. This efficiency translates into faster data processing and lower costs, which is critical for deploying AI in various settings, from mobile devices to server-constrained environments.
Fox-1 is particularly noteworthy for its incorporation into composite AI architectures like Mixture of Experts (MoE) and model federation systems. These configurations leverage multiple SLMs working together to create more powerful systems capable of handling complex tasks such as multilingual processing and predictive analytics from various data sources.
Fox-1’s architecture is a decoder-only transformer-based model with 1.6 billion parameters, trained on a comprehensive dataset comprising 3 trillion tokens of text and code data. The model’s design includes Grouped Query Attention (GQA), enhancing its query processing efficiency and significantly improving inference latency and response times. This advanced architectural design allows Fox-1 to outperform competitors on standard benchmarks, demonstrating its robustness and capability.
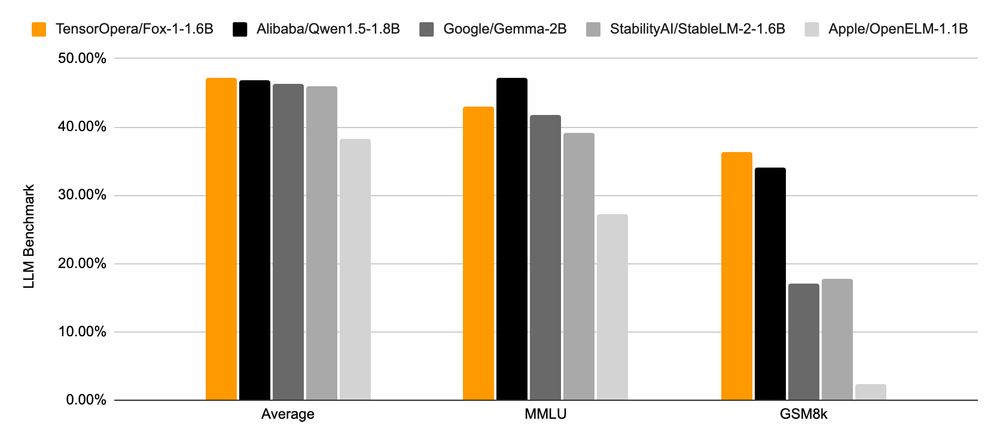
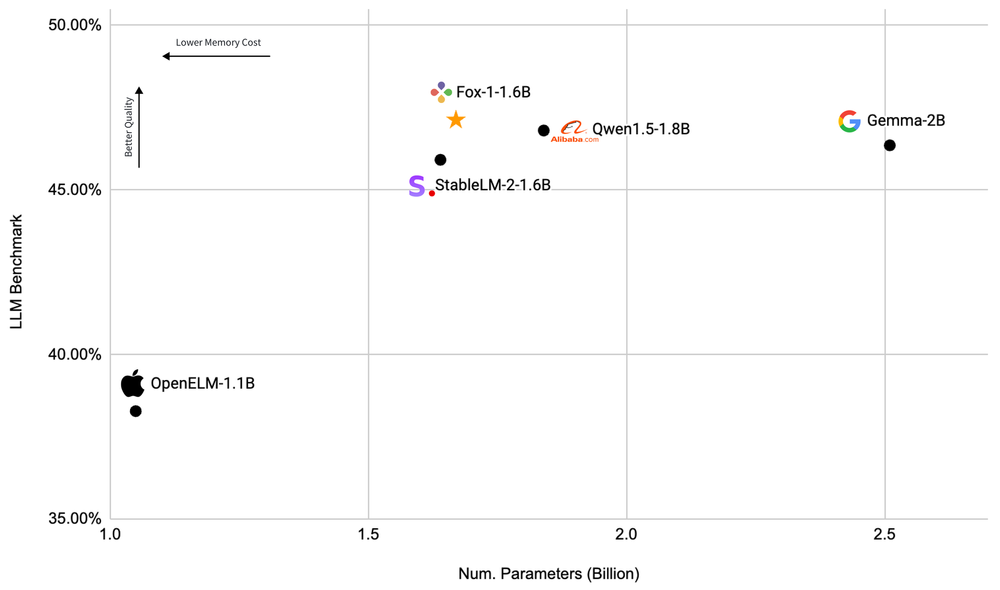
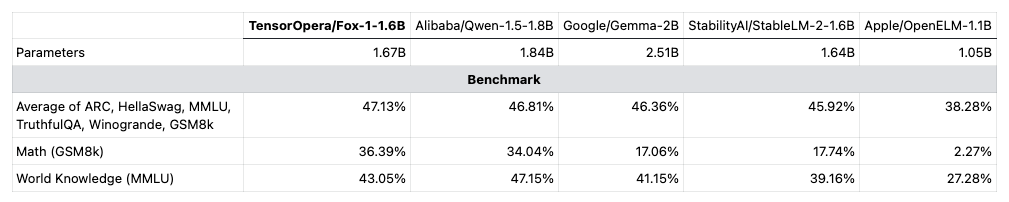
Performance evaluations reveal that Fox-1 excels in various benchmarks, including ARC Challenge, HellaSwag, TruthfulQA, MMLU, Winogrande, and GSM8k. It consistently outperforms models like Gemma-2B, Qwen1.5-1.8B, StableLM-2-1.6B, and OpenELM1.1B, showcasing its superior performance despite having fewer parameters than some.
Regarding inference efficiency, Fox-1 demonstrates impressive throughput, achieving over 200 tokens per second on the TensorOpera model serving platform. This high throughput is attributed to its efficient architectural design, particularly the GQA mechanism. Fox-1’s memory efficiency also makes it suitable for on-device deployment, requiring significantly less GPU memory than its peers.
Integrating Fox-1 into TensorOpera’s product suite enhances its versatility, enabling seamless deployment and training across cloud and edge environments. This integration empowers AI developers to leverage the comprehensive capabilities of the TensorOpera AI Platform for cloud-based training and subsequently deploy and personalize these solutions on edge devices via the TensorOpera FedML platform. This approach offers cost efficiency and enhanced privacy and provides personalized user experiences.
In conclusion, TensorOpera’s Fox-1 is a pioneering model in the SLM landscape, setting new standards for performance and efficiency. Its versatile integration into cloud and edge platforms makes it a formidable tool for developers and enterprises seeking scalable AI solutions. TensorOpera is releasing the base version of Fox-1 under the Apache 2.0 license to facilitate broad adoption, allowing free use for production and research purposes. An instruction-tuned version is also in the pipeline, promising even greater capabilities.
Check out the Model and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post TensorOpera Unveils Fox Foundation Model: A Unique Step in Small Language Models Enhancing Scalability and Efficiency for Cloud and Edge Computing appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #SmallLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]