


Theorem proving in mathematics faces growing challenges due to increasing proof complexity. Formalized systems like Lean, Isabelle, and Coq offer computer-verifiable proofs, but creating these demands substantial human effort. Large language models (LLMs) show promise in solving high-school-level math problems using proof assistants, yet their performance still needs to improve due to data scarcity. Formal languages require significant expertise, resulting in limited corpora. Unlike conventional programming languages, formal proof languages contain hidden intermediate information, making raw language corpora unsuitable for training. This scarcity persists despite the existence of valuable human-written corpora. Auto-formalization efforts, while helpful, cannot fully substitute human-crafted data in quality and diversity.
Existing attempts to address theorem-proving challenges have evolved significantly with modern proof assistants like Coq, Isabelle, and Lean having expanded formal systems beyond first-order logic, increasing interest in automated theorem proving (ATP). The recent integration of large language models has further advanced this field. Early ATP approaches used traditional methods like KNN or GNN, with some employing reinforcement learning. Recent efforts utilize deep transformer-based methods, treating theorems as plain text. Many learning-based systems (e.g., GPT-f, PACT, Llemma) train language models on (proof state, next-tactic) pairs and use tree search for theorem proving. Alternative approaches involve LLMs generating entire proofs independently or based on human-provided proofs. Data extraction tools are crucial for ATP, capturing intermediate states invisible in code but visible during runtime. Tools exist for various proof assistants, but Lean 4 tools face challenges in massive extraction across multiple projects due to single-project design limitations. Some methods also explore incorporating informal proofs into formal proofs, broadening the scope of ATP research.
Researchers from The Chinese University of Hong Kong propose LEAN-GitHub, a large-scale Lean dataset that complements the well-utilized Mathlib dataset. This innovative approach provides an open-source Lean repositories on GitHub, significantly expanding the available data for training theorem-proving models. The researchers developed a scalable pipeline to enhance extraction efficiency and parallelism, enabling the exploitation of valuable data from previously uncompiled and unextracted Lean corpus. Also, they provide a solution to the state duplication problem common in tree-proof search methods.

The LEAN-GitHub dataset construction process involved several key steps and innovations:
- Repository Selection: The researchers identified 237 Lean 4 repositories (GitHub does not differentiate between Lean 3 and Lean 4) on GitHub, estimating approximately 48,091 theorems. After discarding 90 repositories with deprecated Lean 4 versions, 147 remained. Only 61 of these could be compiled without modifications.
- Compilation Challenges: The team developed automated scripts to find the closest official releases for projects using non-official Lean 4 versions. They also addressed the issue of isolated files within empty Lean projects.
- Source Code Compilation: Instead of using the Lake tool, they called the Leanc compiler directly. This approach allowed for compiling non-compliant Lean projects and isolated files, which Lake couldn’t handle. They extended Lake’s import graph and created a custom compiling script with increased parallelism.
- Extraction Process: Building upon LeanDojo, the team implemented data extraction for isolated files and restructured the implementation to increase parallelism. This approach overcame bottlenecks in network connection and computational redundancies.
- Results: Out of 8,639 Lean source files, 6,352 and 42,000 theorems were successfully extracted. The final dataset includes 2,133 files and 28,000 theorems with valid tactic information.
The resulting LEAN-GitHub dataset is diverse, covering various mathematical fields including logic, first-order logic, matroid theory, and arithmetic. It contains cutting-edge mathematical topics, data structures, and Olympiad-level problems. Compared to existing datasets, LEAN-GitHub offers a unique combination of human-written content, intermediate states, and diverse complexity levels, making it a valuable resource for advancing automated theorem proving and formal mathematics.
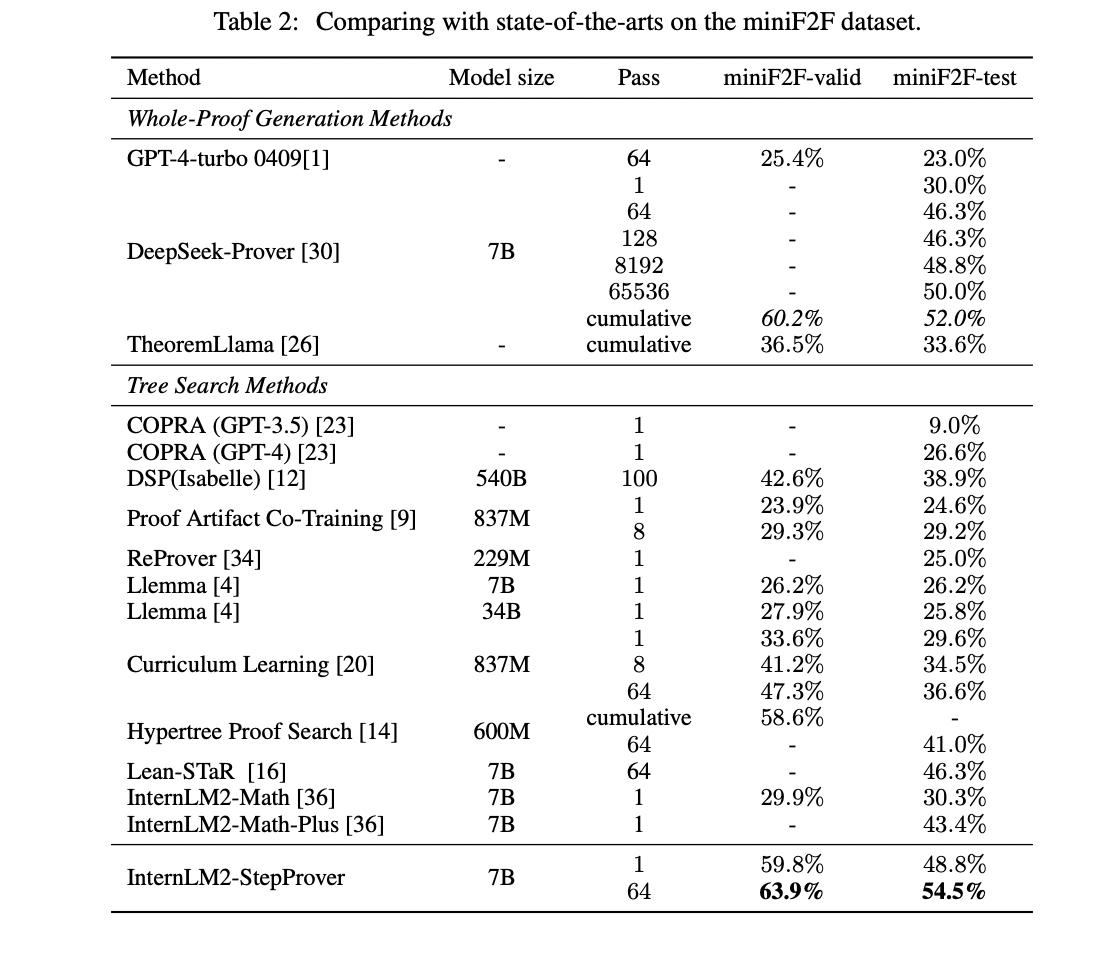
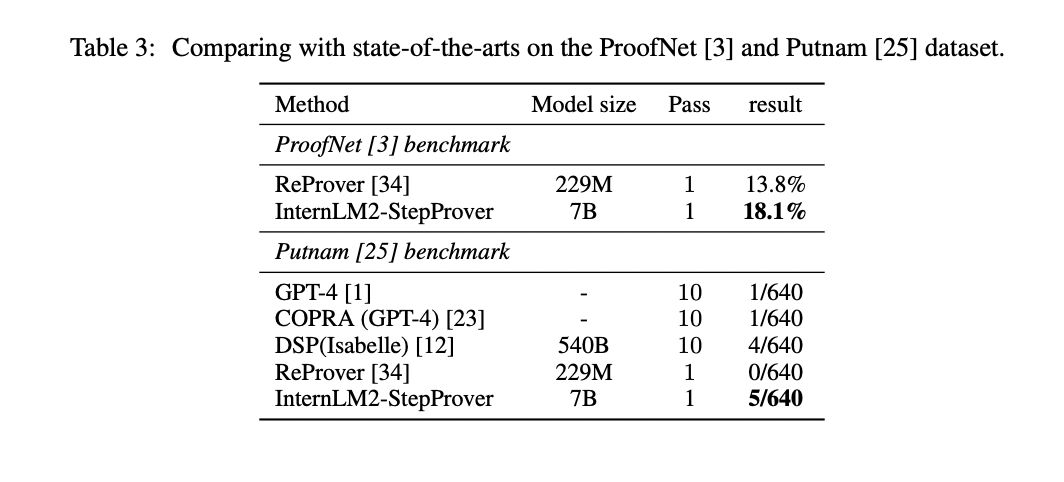
InternLM2-StepProver, trained on the diverse LEAN-GitHub dataset, demonstrates exceptional formal reasoning abilities across various benchmarks. It achieves state-of-the-art performance on miniF2F (63.9% on Valid, 54.5% on Test), surpassing previous models. On ProofNet, it attains an 18.1% Pass@1 rate, outperforming the previous leader. For PutnamBench, it solves 5 problems in a single pass, including the previously unsolved Putnam 1988 B2. These results span high-school to advanced undergraduate-level mathematics, showcasing InternLM2-StepProver’s versatility and the effectiveness of the LEAN-GitHub dataset in training advanced theorem-proving models.
LEAN-GitHub, a large-scale dataset extracted from open Lean 4 repositories, contains 28,597 theorems and 218,866 tactics. This diverse dataset was used to train InternLM2-StepProver, achieving state-of-the-art performance in Lean 4 formal reasoning. Models trained on LEAN-GitHub demonstrate improved performance across various mathematical fields and difficulty levels, highlighting the dataset’s effectiveness in enhancing reasoning capabilities. By open-sourcing LEAN-GitHub, the researchers aim to help the community better utilize under-exploited information in raw corpora and advance mathematical reasoning. This contribution could significantly accelerate progress in automated theorem proving and formal mathematics.
Check out the Paper and Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post LEAN-GitHub: A Large-Scale Dataset for Advancing Automated Theorem Proving appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]