


Video large language models (LLMs) have emerged as powerful tools for processing video inputs and generating contextually relevant responses to user commands. However, these models face significant challenges in their current methodologies. The primary issue lies in the high computational and labeling costs associated with training on supervised fine-tuning (SFT) video datasets. Also, existing Video LLMs struggle with two main drawbacks: they are limited in their ability to process a large number of input frames, hindering the capture of fine-grained spatial and temporal content throughout videos, and they lack proper temporal modeling design, relying solely on the LLM’s capability to model motion patterns without specialized video processing components.
Researchers have attempted to solve video processing challenges using various LLM approaches. Image LLMs like Flamingo, BLIP-2, and LLaVA demonstrated success in visual-textual tasks, while Video LLMs such as Video-ChatGPT and Video-LLaVA extended these capabilities to video processing. However, these models often require expensive fine-tuning on large video datasets. Training-free methods like FreeVA and IG-VLM emerged as cost-efficient alternatives, utilizing pre-trained Image LLMs without additional fine-tuning. Despite promising results, these approaches still struggle with processing longer videos and capturing complex temporal dependencies, limiting their effectiveness in handling diverse video content.
Apple researchers present SF-LLaVA, a unique training-free Video LLM that addresses the challenges in video processing by introducing a SlowFast design inspired by successful two-stream networks for action recognition. This approach captures both detailed spatial semantics and long-range temporal context without requiring additional fine-tuning. The Slow pathway extracts features at a low frame rate with higher spatial resolution, while the Fast pathway operates at a high frame rate with aggressive spatial pooling. This dual-pathway design balances modeling capability and computational efficiency, enabling the processing of more video frames to preserve adequate details. SF-LLaVA integrates complementary features from slowly changing visual semantics and rapidly changing motion dynamics, providing a comprehensive understanding of videos and overcoming the limitations of previous methods.
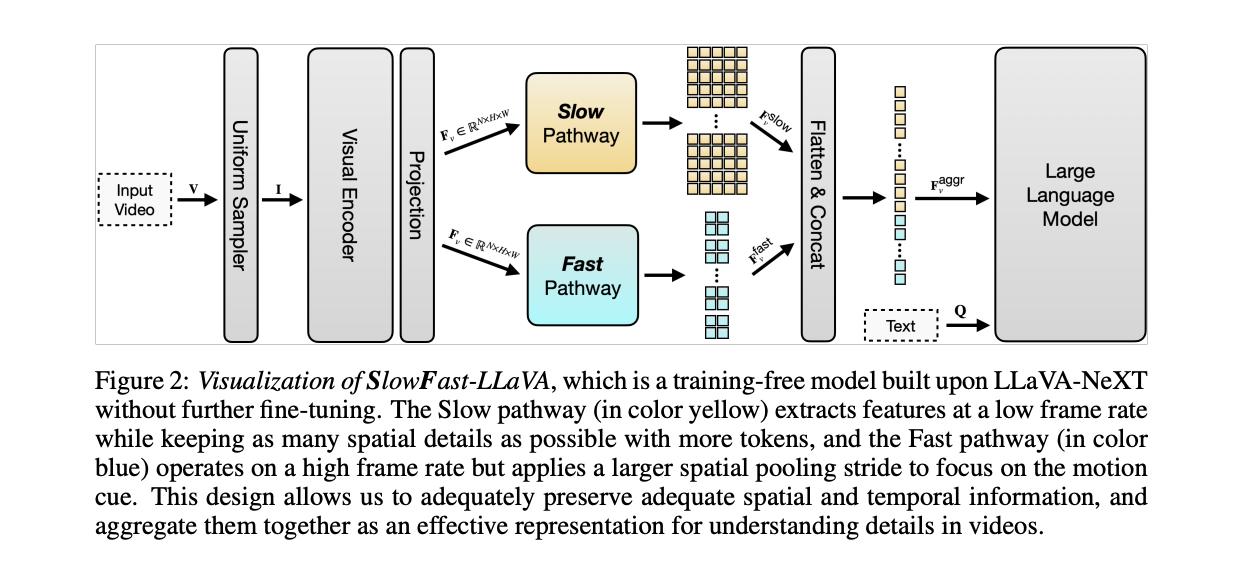
SlowFast-LLaVA (SF-LLaVA) introduces a unique SlowFast architecture for training-free Video LLMs, inspired by two-stream networks for action recognition. This design effectively captures both detailed spatial semantics and long-range temporal context without exceeding the token limits of common LLMs. The Slow pathway processes high-resolution but low-frame-rate features (e.g., 8 frames with 24×24 tokens each) to capture spatial details. Conversely, the Fast pathway handles low-resolution but high-frame-rate features (e.g., 64 frames with 4×4 tokens each) to model broader temporal context. This dual-pathway approach allows SF-LLaVA to preserve both spatial and temporal information, aggregating them into a powerful representation for comprehensive video understanding without requiring additional fine-tuning.
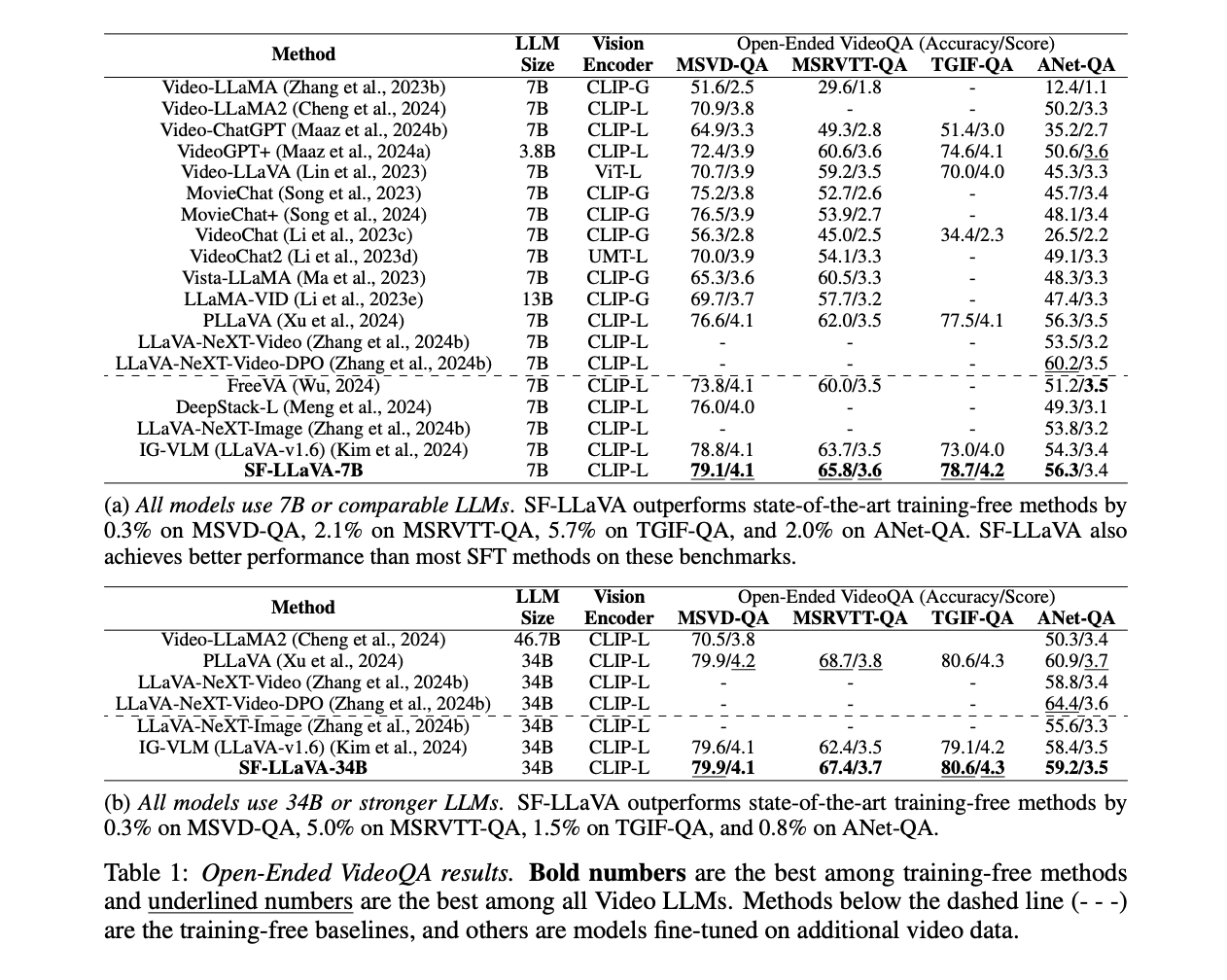
SF-LLaVA demonstrates impressive performance across various video understanding tasks, often surpassing state-of-the-art training-free methods and competing with SFT models. In open-ended VideoQA tasks, SF-LLaVA outperforms other training-free methods on all benchmarks, with improvements of up to 5.7% on some datasets. For multiple-choice VideoQA, SF-LLaVA shows significant advantages, particularly on complex long-form temporal reasoning tasks like EgoSchema, where it outperforms IG-VLM by 11.4% using a 7B LLM. In text generation tasks, SF-LLaVA-34B surpasses all training-free baselines on average and excels in temporal understanding. While SF-LLaVA occasionally falls short in capturing fine spatial details compared to some methods, its SlowFast design allows it to cover longer temporal contexts efficiently, demonstrating superior performance in most tasks, especially those requiring temporal reasoning.
This research introduces SF-LLaVA, a unique training-free Video LLM, presenting a significant leap in video understanding without the need for additional fine-tuning. Built upon LLaVA-NeXT, it introduces a SlowFast design that utilizes two-stream inputs to capture both detailed spatial semantics and long-range temporal context effectively. This innovative approach aggregates frame features into a comprehensive video representation, enabling SF-LLaVA to perform exceptionally well across various video tasks. Extensive experiments across 8 diverse video benchmarks demonstrate SF-LLaVA’s superiority over existing training-free methods, with performance often matching or exceeding state-of-the-art supervised fine-tuned Video LLMs. SF-LLaVA not only serves as a strong baseline in the field of Video LLMs but also offers valuable insights for future research in modeling video representations for Multimodal LLMs through its design choices.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post SF-LLaVA: A Training-Free Video LLM that is Built Upon LLaVA-NeXT and Requires No Additional Fine-Tuning to Work Effectively for Various Video Tasks appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]