


Multi-target multi-camera tracking (MTMCT) is essential for intelligent transportation systems. Still, it faces challenges in real-world applications due to limited publicly available data and the labor-intensive process of manual annotation. Efficient traffic management has been improved with advancements in computer vision, enabling accurate prediction and analysis of traffic volumes. MTMCT involves tracking vehicles across multiple cameras by detecting objects, performing multi-object tracking within single cameras, and finally clustering trajectories to create a global map of vehicle movements. Despite its potential, MTMCT faces issues such as the need for new matching rules for each camera scenario, limited datasets, and high costs associated with manual labeling.
Researchers from the University of Tennessee at Chattanooga and the L3S Research Center at Leibniz University Hannover have developed LaMMOn, an end-to-end multi-camera tracking model based on transformers and graph neural networks. LaMMOn integrates three modules: the Language Model Detection (LMD) for object detection, the Language and Graph Model Association (LGMA) for tracking and trajectory clustering, and the Text-to-embedding (T2E) module for generating object embeddings from text to address data limitations. This model performs well on various datasets, including CityFlow and TrackCUIP, with competitive results and acceptable real-time processing speeds. LaMMOn’s design eliminates the need for new matching rules and manual labeling by leveraging synthesized embeddings from text.
Multi-Object Tracking (MOT) involves associating objects across video frames from a single camera to create tracklets, with methods like Tracktor, CenterTrack, and TransCenter enhancing tracking capabilities. MTMCT extends this by integrating object movements across multiple cameras, often treating MTMCT as a clustering extension of MOT results. Techniques like spatial-temporal filtering and traffic law constraints have improved accuracy, though LaMMOn distinguishes itself by combining detection and association tasks end-to-end. Transformer models such as Trackformer and TransTrack, alongside GNNs like GCN and GAT, have been utilized to advance tracking performance, including handling complex data structures and optimizing multi-camera tracking.
The LaMMOn framework consists of three key modules: the LMD module, which detects objects and generates embeddings; the LGMA module, which handles multi-camera tracking and trajectory clustering; and the T2E module, which synthesizes object embeddings from text descriptions. The LMD combines video frame inputs with positional and camera ID embeddings to produce object embeddings using Deformable DETR. LGMA uses these embeddings to perform global tracklist association via graph-based token features. The T2E module, based on Sentencepiece, generates synthetic embeddings from text, addressing data limitations and reducing labeling costs.
The LaMMOn model was evaluated on three MTMCT tracking datasets: CityFlow, I24, and TrackCUIP. On CityFlow, LaMMOn achieved an IDF1 score of 78.83% and a HOTA score of 76.46% with an FPS of 12.2, surpassing other methods such as TADAM and BLSTM-MTP. For the I24 dataset, LaMMOn excelled with a HOTA of 25.7 and a Recall of 79.4, demonstrating superior performance over previous models. The TrackCUIP results also highlight LaMMOn’s effectiveness, with notable improvements of 4.42% in IDF1 and 2.82% in HOTA compared to other baseline methods while maintaining an efficient FPS.
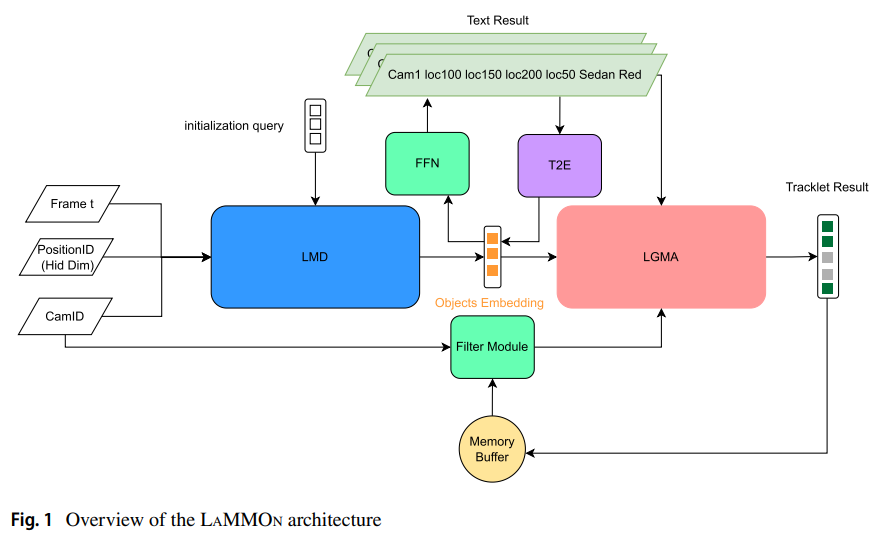
The LaMMOn model presents an end-to-end multi-camera tracking solution leveraging transformers and graph neural networks. It addresses the limitations of tracking-by-detection with a generative approach that minimizes manual labeling by synthesizing object embeddings from text descriptions facilitated by the LMD and T2E modules. The trajectory clustering method using Language and LGMA enhances trackless generation and adaptability across various traffic scenarios. Demonstrating real-time online capabilities, LaMMOn achieves competitive performance with CityFlow (IDF1 78.83%, HOTA 76.46%), I24 (HOTA 25.7%), and TrackCUIP (IDF1 81.83%, HOTA 80.94%).
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post LaMMOn: An End-to-End Multi-Camera Tracking Solution Leveraging Transformers and Graph Neural Networks for Enhanced Real-Time Traffic Management appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]