


As large language models surpass human-level capabilities, providing accurate supervision becomes increasingly difficult. Weak-to-strong learning, which uses a less capable model to enhance a stronger one, offers potential benefits but needs testing for complex reasoning tasks. This method currently lacks efficient techniques to prevent the stronger model from imitating the weaker model’s errors. As AI progresses toward Artificial General Intelligence (AGI), creating superintelligent systems introduces significant challenges, particularly in supervision and learning paradigms. Conventional methods relying on human oversight or advanced model guidance become inadequate as AI capabilities surpass those of their supervisors.
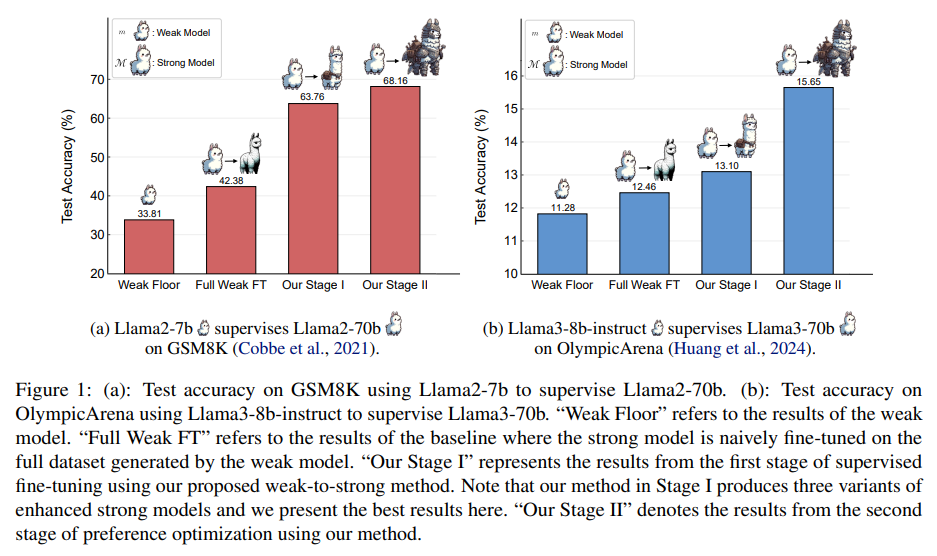
Researchers from Shanghai Jiao Tong University, Fudan University, Shanghai AI Laboratory, and GAIR have developed a progressive learning framework that allows strong models to refine their training data autonomously. This approach begins with supervised fine-tuning on a small, high-quality dataset, followed by preference optimization using contrastive samples identified by the strong model. Experiments on the GSM8K and MATH datasets show significant improvements in the reasoning abilities of Llama2-70b using three different weak models. The framework’s effectiveness is further demonstrated with Llama3-8b-instruct supervising Llama3-70b on the challenging OlympicArena dataset, paving the way for enhanced AI reasoning strategies.
LLMs enhance task-solving and alignment with human instructions through supervised fine-tuning (SFT), which relies on high-quality training data for substantial performance gains. This study examines the potential of learning from weak supervision. Aligning LLMs with human values also requires RLHF and direct preference optimization (DPO). DPO simplifies reparameterizing reward functions in RLHF and has various stable and performant variants like ORPO and SimPO. In mathematical reasoning, researchers focus on prompting techniques and generating high-quality question-answer pairs for fine-tuning, significantly improving problem-solving capabilities.
The weak-to-strong training method aims to maximize the use of weak data and enhance the strong model’s abilities. In Stage I, potentially positive samples are identified without ground truth and used for supervised fine-tuning. Stage II involves using the full weak data, focusing on potentially negative samples through preference learning-based approaches like DPO. This method refines the strong model by learning from the weak model’s mistakes. The strong model’s responses are sampled, and confidence levels are used to determine reliable answers. Contrastive samples are created for further training, helping the strong model differentiate between correct and incorrect solutions, resulting in an improved model.
The experiments utilize GSM8K and MATH datasets, with subsets Dgold,1, and Dgold, two used for training weak and strong models. Initial training on GSM8K was enhanced with additional data, while MATH data faced limitations due to its complexity. Iterative fine-tuning improved weak models, which subsequently elevated strong model performance. Using preference learning methods, significant improvements were observed, particularly on GSM8K. Further analysis showed better generalization on simpler problems. Tests with Llama3 models on OlympicArena, a more challenging dataset, demonstrated that the proposed weak-to-strong learning method is effective and scalable in realistic scenarios.
In conclusion, the study investigates the effectiveness of the weak-to-strong framework in complex reasoning tasks, presenting a method that leverages weak supervision to develop strong capabilities without human or advanced model annotations. The strong model refines its training data independently, even without prior task knowledge, progressively enhancing its reasoning skills through iterative learning. This self-directed data curation is essential for advancing AI reasoning capabilities promoting model independence and efficiency. The study highlights innovative model supervision’s role in AI development, particularly for AGI. Limitations include using current models as proxies for future advanced models and the challenges posed by errors and noise in process-level supervision.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Progressive Learning Framework for Enhancing AI Reasoning through Weak-to-Strong Supervision appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]