


Large Language Models (LLMs) have revolutionized natural language processing, demonstrating remarkable capabilities in various applications. However, these models face significant challenges, including temporal limitations of their knowledge base, difficulties with complex mathematical computations, and a tendency to produce inaccurate information or “hallucinations.” These limitations have spurred researchers to explore innovative solutions that can enhance LLM performance without the need for extensive retraining. The integration of LLMs with external data sources and applications has emerged as a promising approach to address these challenges, aiming to improve accuracy, relevance, and computational capabilities while maintaining the models’ core strengths in language understanding and generation.
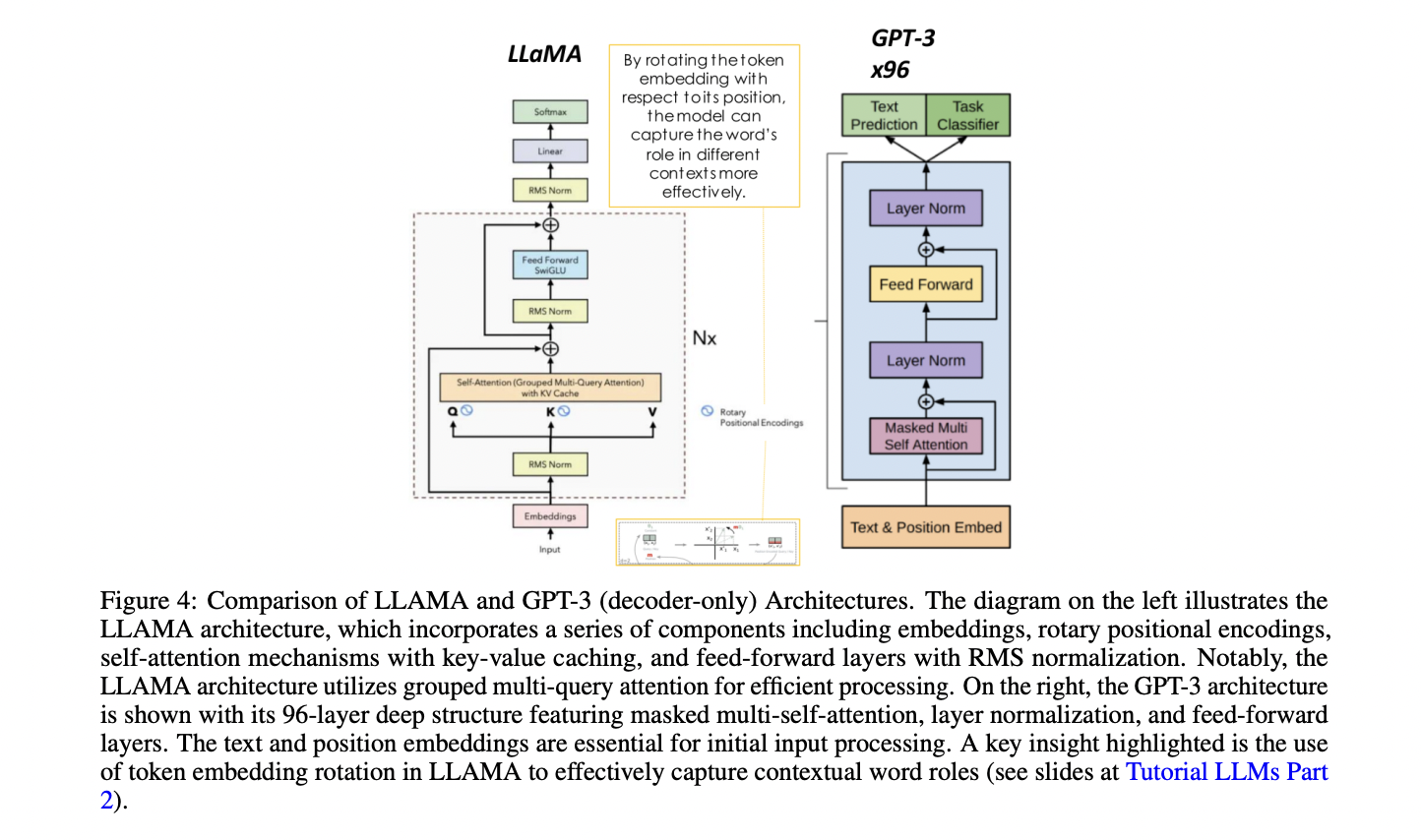
Transformer architecture has emerged as a major leap in natural language processing, significantly outperforming earlier recurrent neural networks. The key to this success lies in the transformer’s self-attention mechanism, which allows the model to consider the relevance of each word to every other word in a sentence, capturing complex dependencies and contextual information. Transformers consist of encoder and decoder components, each comprising multiple layers with self-attention mechanisms and feed-forward neural networks. The architecture processes tokenized input through embedding layers, applies multi-headed self-attention, and incorporates positional encoding to retain sequence order information. Various transformer-based models have been developed for specific tasks, including encoder-only models like BERT for text understanding, encoder-decoder models such as BART and T5 for sequence-to-sequence tasks, and decoder-only models like the GPT family for text generation. Recent advancements focus on scaling up these models and developing techniques for efficient fine-tuning, expanding their applicability across diverse domains.
Sr. Research Scientist Giorgio Roffo presents a comprehensive exploration of the challenges faced by LLMs and innovative solutions to address them. The researchers introduce Retrieval Augmented Generation (RAG) as a method to access real-time external information, enhancing LLM performance across various applications. They discuss the integration of LLMs with external applications for complex tasks and explore chain-of-thought prompting to improve reasoning capabilities. The paper delves into frameworks like Program-Aided Language Model (PAL), which pairs LLMs with external code interpreters for accurate calculations, and examines advancements such as ReAct and LangChain for solving intricate problems. The researchers also outline architectural components for developing LLM-powered applications, covering infrastructure, deployment, and integration of external information sources. The paper provides insights into various transformer-based models, techniques for scaling model training, and fine-tuning strategies to enhance LLM performance for specific use cases.
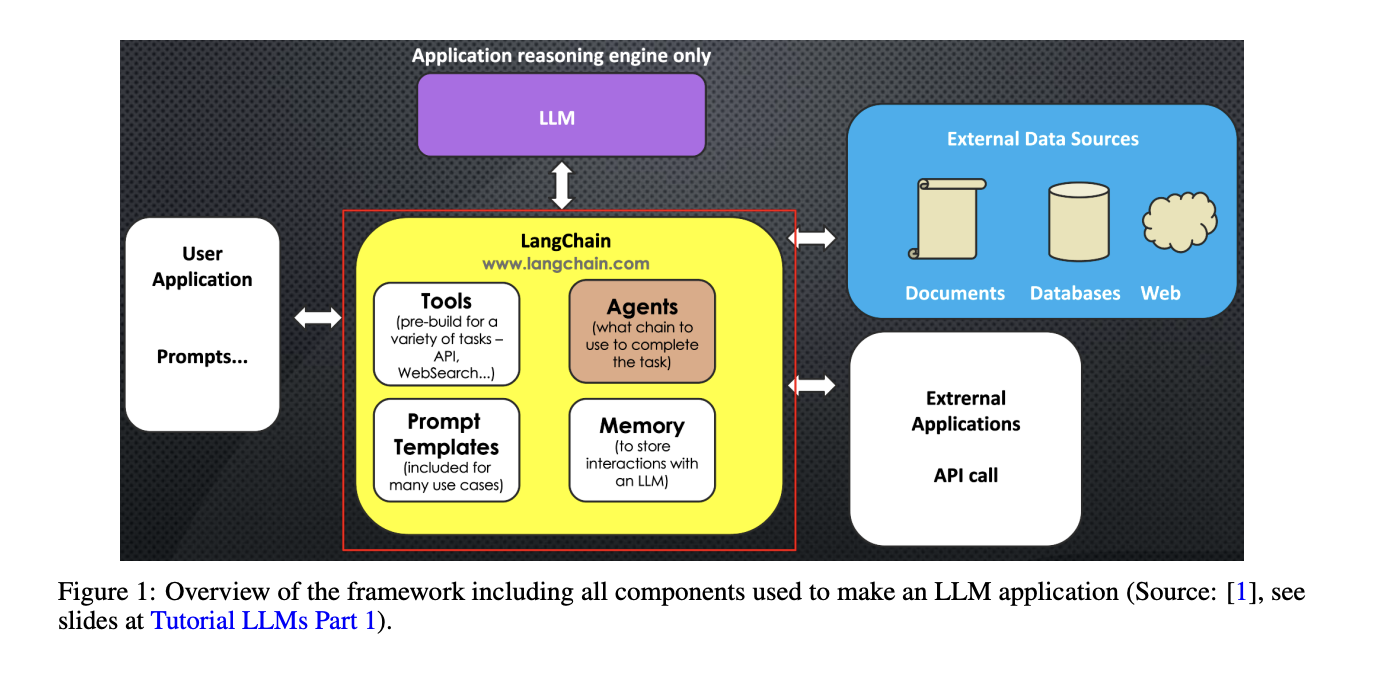
The perception that modern generative AI systems like ChatGPT and Gemini are merely LLMs oversimplifies their sophisticated architecture. These systems integrate multiple frameworks and capabilities that extend far beyond standalone LLMs. At their core lies the LLM, serving as the primary engine for generating human-like text. However, this is just one component within a broader, more complex framework.
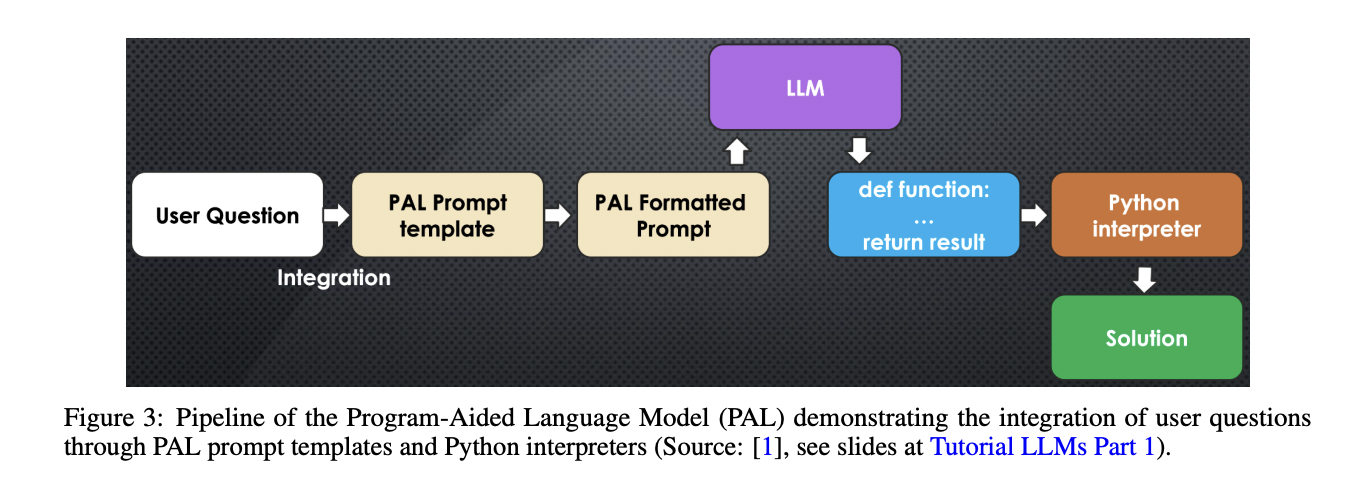
Tools like Retrieval-Augmented Generation (RAG) enhance the model’s capabilities by enabling it to fetch information from external sources. Techniques such as Chain of Thought (CoT) and Program-Aided Language models (PAL) further improve reasoning capabilities. Frameworks like ReAct (Reasoning and Acting) enable AI systems to plan and execute strategies for problem-solving. These components work in concert, creating an intricate ecosystem that delivers more sophisticated, accurate, and contextually relevant responses, far exceeding the capabilities of standalone language models.
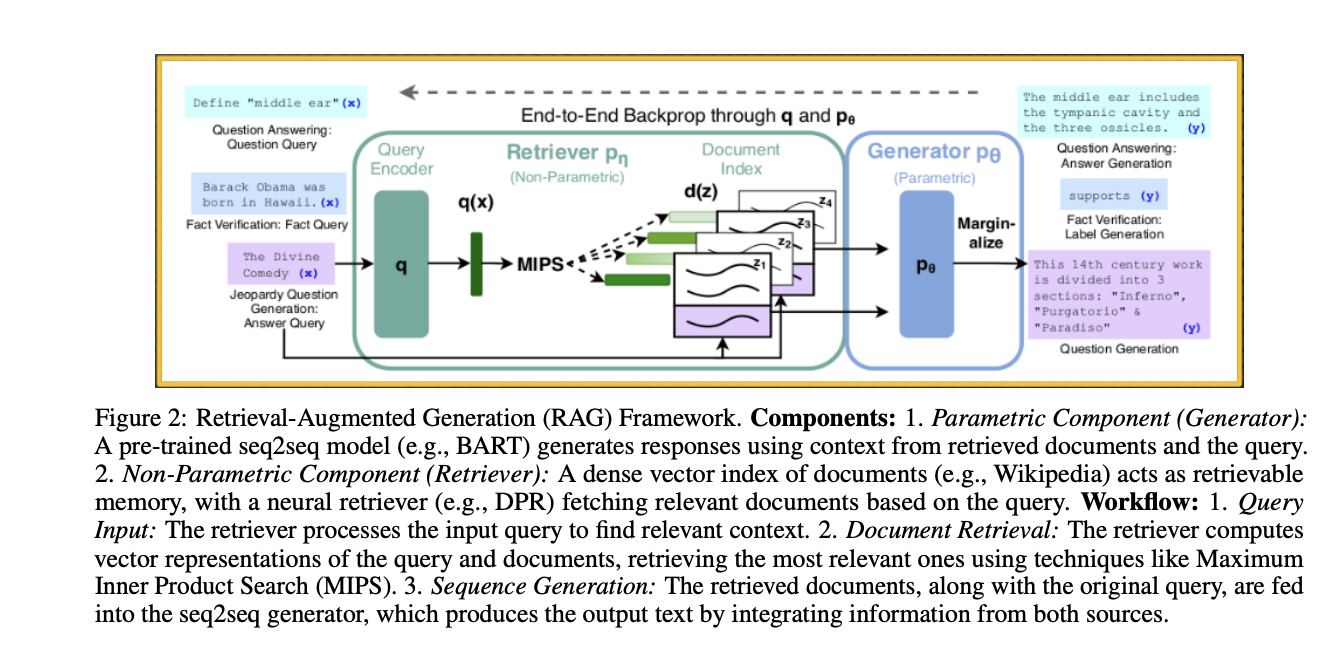
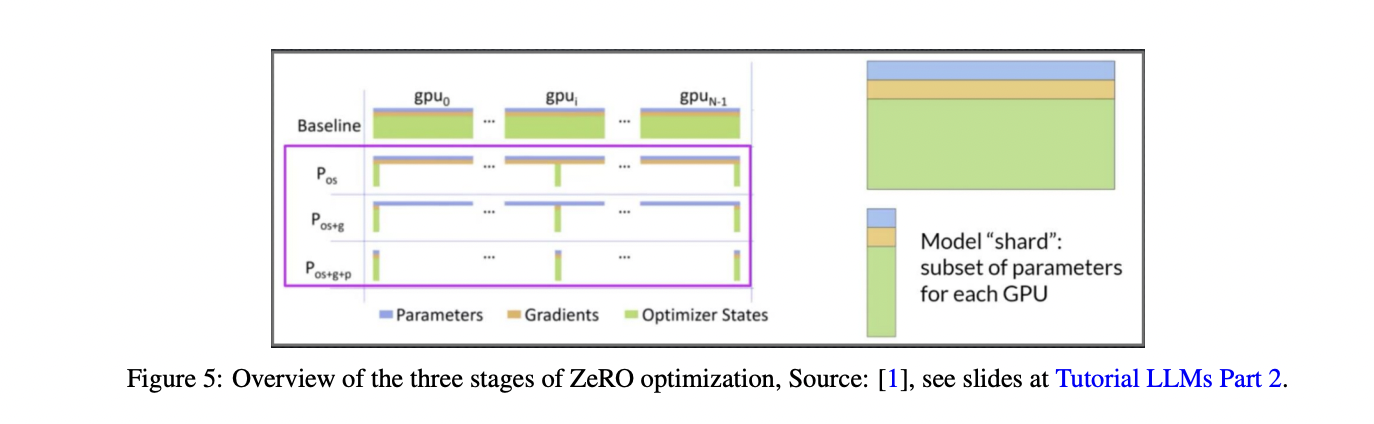
Current advancements in LLM training focus on efficient scaling across multiple GPUs. Techniques like Distributed Data Parallel (DDP) and Fully Sharded Data Parallel (FSDP) distribute computations and model components across GPUs, optimizing memory usage and training speed. FSDP, inspired by the ZeRO (Zero Redundancy Optimizer) framework, introduces three stages of optimization to shard model states, gradients, and parameters. These methods enable the training of larger models and accelerate the process for smaller ones. Also, the development of 1-bit LLMs, such as BitNet b1.58, offers significant improvements in memory efficiency, inference speed, and energy consumption while maintaining performance comparable to traditional 16-bit models.
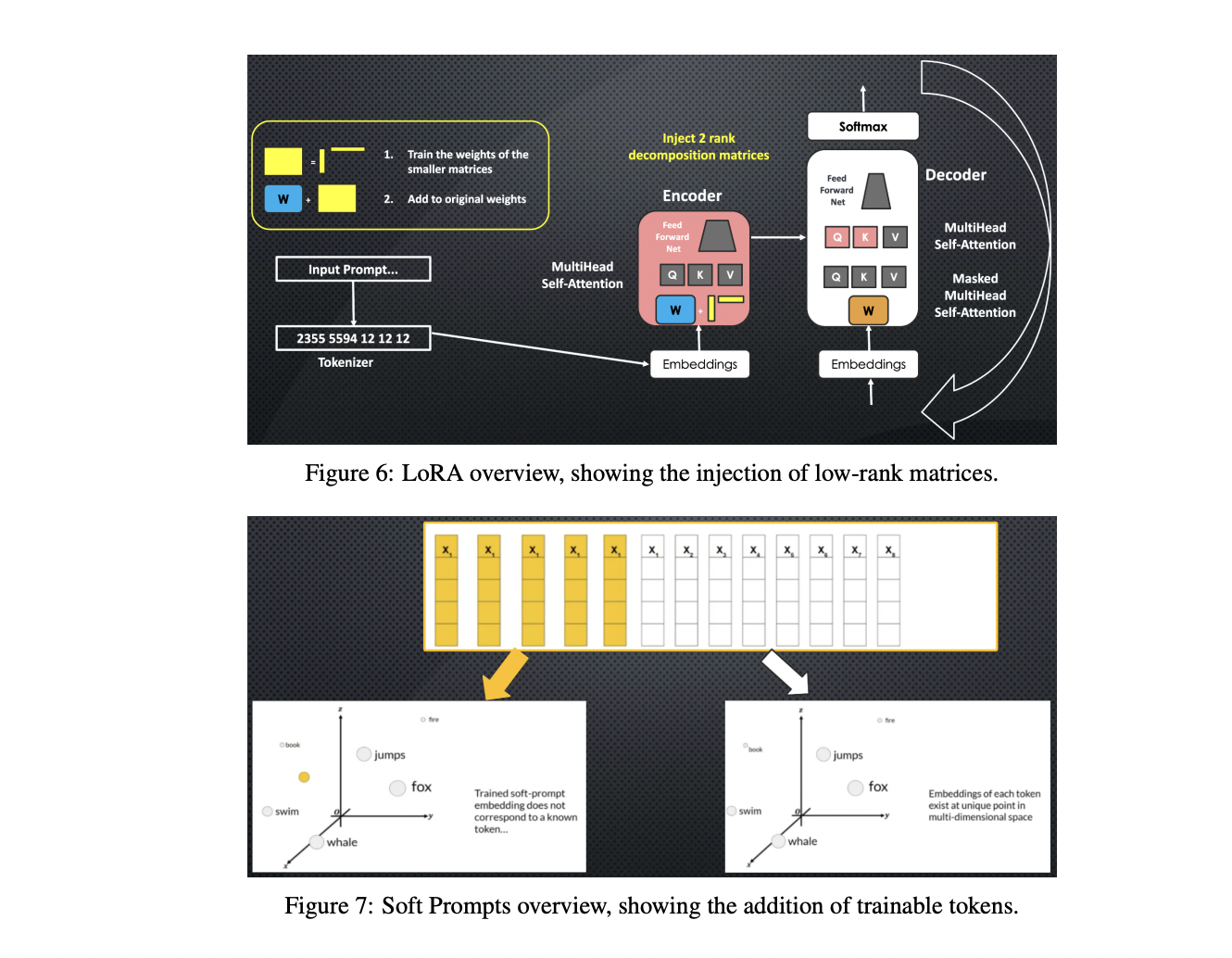
Fine-tuning techniques enhance Large Language Models’ performance for specific tasks. Instruction fine-tuning uses prompt-completion pairs to update model weights, improving task-specific responses. Multitask fine-tuning mitigates catastrophic forgetting by simultaneously training on multiple tasks. PEFT methods like Low-Rank Adaptation (LoRA) and prompt tuning reduce computational demands while maintaining performance. LoRA introduces low-rank decomposition matrices, while prompt tuning adds trainable soft prompts. These techniques significantly reduce the number of trainable parameters, making fine-tuning more accessible and efficient. Future research aims to optimize the balance between parameter efficiency and model performance, exploring hybrid approaches and adaptive PEFT methods.
Reinforcement Learning from Human Feedback (RLHF) and Reinforced Self-Training (ReST) are advanced techniques for aligning large language models with human preferences. RLHF uses human feedback to train a reward model, which guides the language model’s policy optimization through reinforcement learning algorithms like Proximal Policy Optimization (PPO). ReST introduces a two-loop structure: a Grow step generating output predictions, and an Improve step filtering and fine-tuning on this dataset using offline RL. RLHF offers direct alignment but faces high computational costs and potential reward hacking. ReST provides efficiency and stability by decoupling data generation and policy improvement. Both methods significantly enhance model performance, with ReST showing particular promise in large-scale applications. Future research may explore hybrid approaches combining their strengths.
This tutorial paper provides a comprehensive overview of recent advancements in LLMs and addresses their inherent limitations. It introduces innovative techniques like RAG for accessing current external information, PAL for precise computations, and LangChain for efficient integration with external data sources. The paper explores fine-tuning strategies, including instruction fine-tuning and parameter-efficient methods like LoRA and prompt tuning. It also discusses alignment techniques such as RLHF and ReST. Also, the paper covers transformer architectures, scaling techniques for model training, and practical applications. These advancements collectively aim to enhance LLM performance, reliability, and applicability across various domains, paving the way for more sophisticated and contextually relevant AI interactions.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
The post From RAG to ReST: A Survey of Advanced Techniques in Large Language Model Development appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]