


The semantic capabilities of modern language models offer the potential for advanced analytics and reasoning over extensive knowledge corpora. However, current systems need more high-level abstractions for large-scale semantic queries. Complex tasks like summarizing recent research, extracting biomedical information, or analyzing internal business transcripts require sophisticated data processing and reasoning. Existing methods, such as retrieval-augmented generation (RAG), are limited to simple lookups and do not support more complex query patterns.
Researchers from Stanford University, USA, and UC Berkeley have developed semantic operators, a declarative programming interface that enhances the relational model with AI-driven operations for semantic queries over datasets. These operators are implemented in LOTUS, an open-source query engine with a Pandas-like API, enabling the creation of efficient and expressive query pipelines. LOTUS has proven effective in various applications, including fact-checking, multi-label classification, and search, delivering significant improvements in accuracy and execution time. For instance, in fact-checking on the FEVER dataset, LOTUS programs increase accuracy by up to 9.5% and reduce execution time by 7 to 34 times compared to current state-of-the-art pipelines.
Several prior works have extended relational languages with LM-based operations for specialized tasks. For instance, Palimpzest offers a declarative approach to data cleaning and ETL tasks, introducing a convert operator for entity extraction and an AI-based filter. SUQL extends SQL to support conversational agents with new operators to answer questions and summarize data. ZenDB and EVAPORATE focus on extracting semi-structured documents into structured tables. In contrast, LOTUS provides a general-purpose programming model with composable semantic operators for diverse applications. It supports complex query patterns, including joins, aggregation, ranking, and search functions, beyond the capabilities of row-wise LLM UDFs.
The LOTUS programming model allows developers to create AI-driven query pipelines for processing large datasets of structured and unstructured data. It extends the relational model with semantic operators, enhancing functionality through an API built on Pandas. These operators include `sem_filter` for filtering, `sem_join` for joining tables, `sem_sim_join` for similarity joins, and others for aggregation, ranking, and clustering. LOTUS supports natural language expressions (langex) for specifying these operations, enabling intuitive and declarative programming. The model incorporates optimization techniques like batched inference, model cascades, and semantic similarity indices to handle complex queries and improve performance efficiently.
The evaluation of LOTUS focuses on its programmability and efficiency across three applications: fact-checking, extreme multi-label classification, and search and ranking. Each application demonstrates that state-of-the-art results are achievable with minimal development overhead using LOTUS programs. For instance, LOTUS can reproduce and enhance the accuracy of a recent fact-checking pipeline by 9.5% while significantly reducing execution time. LOTUS achieves up to 800× faster performance in extreme multi-label classification than traditional methods. In search and ranking, LOTUS outperforms other methods in nDCG@10 by up to 49.4% while also being more rapid. Experiments were conducted using various models and setups, including Llama 3 models on 4 A100 GPUs.
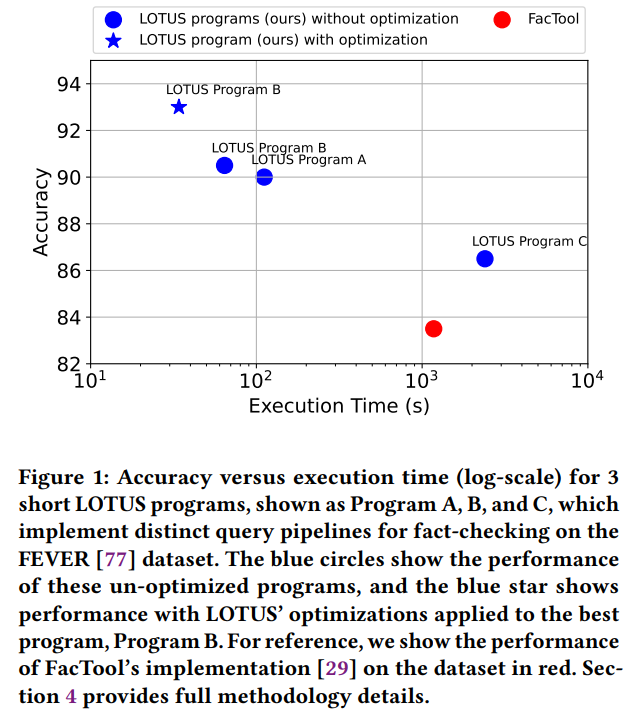
In conclusion, the study introduces semantic operators, providing the first declarative, general-purpose interface for bulk-semantic processing. Implemented in the LOTUS system, these operators extend the relational model, allowing easy composition of advanced reasoning-based query pipelines over large datasets. LOTUS demonstrates effectiveness across applications like fact-checking, extreme multi-label classification, and search, showing its programming model’s expressiveness and low development overhead. For example, LOTUS improves accuracy by 9.5% on the FEVER dataset and reduces execution time significantly. LOTUS achieves state-of-the-art results with substantial efficiency gains in multi-label classification and search tasks, highlighting its optimization capabilities and potential for rich analytics over vast knowledge corpora.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
The post LOTUS: A Query Engine for Reasoning over Large Corpora of Unstructured and Structured Data with LLMs appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #Databases #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]